Hi, everyone -
Here in Toronto we’re enjoying the traditional season of “False Spring”, where a burst of warm weather and blue skies lures the unwary into putting away winter coats - but even so it’s cheering and encouraging, and spirits everywhere are notably lifted.
I’m going to write a little bit about performance management in the next three newsletters. I have a brief introduction to my preferred philosophy of performance management below (or skip to the roundup); in the next issue we’ll talk a bit about short-term performance management (feedback) in the following we’ll talk about longer-term performance (goal-setting and review), and finally we’ll talk about what happens if people are or aren’t consistently meeting expectations.
When talking about performance management, especially with new managers, I generally prefer to avoid the word performance as much as possible at the beginning, instead talking about communicating expectations. I find this clarifying for a number of reasons:
The thing is, almost all of the team members you will ever work with want to meet your expectations, and are capable or can become capable of meeting them.
New team members, or team members new to particular responsibilities, won’t know what those expectations are. Even experienced team members who do know all the relevant expectations might not know which of several competing expectations are the most important in some particular situations.
As a manager you certainly communicate expectations when assigning goal - but you won’t be able to list every single relevant expectations for every single task every single time someone does something. Those expectations are still there, though, and they need to be consistently met over time. So in addition to taking about expectations before hand it’s important to be able to talk about them afterwards too. In both cases, it’s about guiding future behaviour.
Short-term feedback, and long-term goal-setting and review, are fundamentally about describing your expectations, and recognizing team members efforts as meeting or not meeting those expectations. The resulting conversations are about helping your team members meet your expectations in the future. In some cases - especially as you find yourself working in new areas - it will also be in part about recalibrating your expectations.
Next time we’ll talk about a couple of common formulations for having those conversations around immediate and short-term expectations - giving feedback.
Thoughts on Engineering Management - Ben McCormick
McCormick writes a series of five articles on technical computing management. The broad topics won’t be a huge surprise to readers, but they’re good reads in that they’re all in a very coherent voice and philosophy:
Does it KLAPS? An OKR Rubric - Debra Roberts
You’ve almost certainly heard of SMART goals - a rubric for defining good goals for work. They’re variously defined as some combination of Specific, Measurable, Achievable/Acceptable/Assignable, Relevant/Realistic and Time-based. The fact that A and R’s meanings change from telling to telling suggest, correctly, that they’re not essential. The important thing is - is the goal specific enough that a third party could assess whether it’s met or not? Can you actually measure it, and if so, what’s the metric? And is there a deadline? A goal without a deadline and a way of checking to see if you made it is merely an aspiration.
OKRs - Objectives and Key Results - are like goals for organizations; and they cascade down, to keep sizable organizations aligned and all moving in the same direction. There’s an clearly written (Specific) Objective for the quarter or year (Time-based) with three or four quantitative (Measurable) Key Results that let the organization know if they’re getting there. Higher-ups set the OKR for the organization, and then teams below set their own OKRs so as to support the OKRs above, and so on.
Roberts suggests a rubric for OKRs similar to SMART for goals. Many of us work in teams that are small enough we don’t need OKRs for alignment, but much of what Roberts suggests is useful even for team-based metrics, which we’ve talked about before. Roberts’ rubric is:
Even just for metrics for individual teams, knowable, autonomous, and progressive are important; leading is good too although lagging has its place.
Digital skills for FAIR and open science: Report from the EOSC Skills and Training Working Group - EU Secretariat
For years, the focus for digital research infrastructure was on stuff, not people. Stuff - computing, storage - definitely is needed, but none of matters without the teams to operate them, write the sofware, to train and support the researchers, to curate the data, etc.
The RSE (Research Software Engineer) movement has successfully raised the profile of software developers and the need for hiring and training them, and for them to have meaningful career ladders; and that’s all to the good. But a recurring theme of the newsletter is that focussing on one aspect of research computing and data while omitting the others is a mistake. The various sub-disciplines - sofware, systems, data management - are interlocking and mutually reinforcing, while boundaries between the disciplines are blurring if they were ever sharp at all.
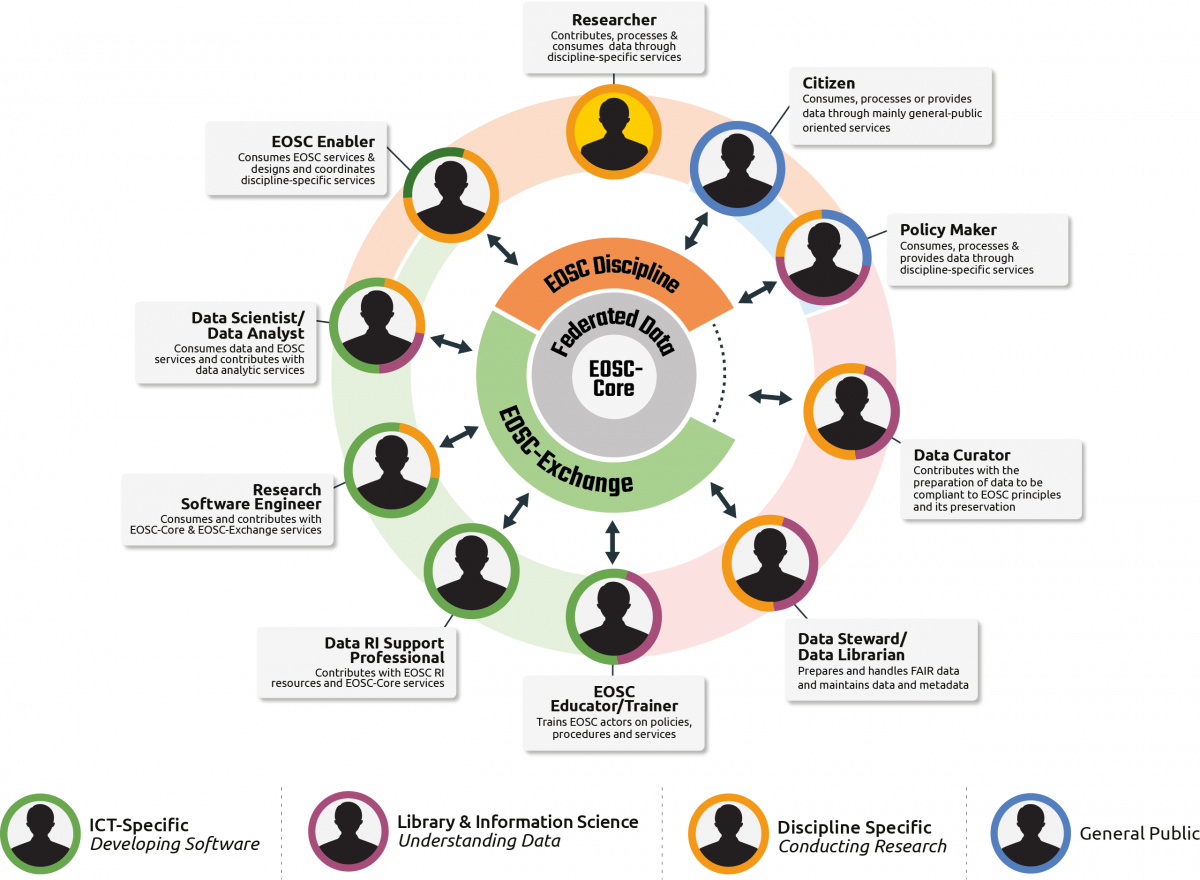
This EOSC report looks at skills and training needed by staff, trainees, and researchers for the European Open Source Cloud as a whole, with a focus on FAIR and Open science in particular. It takes a look at the set of skills needed in exactly that interlocking and mutually reinforcing way, and involving a wide number of different roles and actors. While I don’t think the recommendations made would surprise most readers, it’s nice to see the framework of actors (the figure above) explicitly laid out.
Rust vs. Go: Why They’re Better Together - Jonathan Turner and Steve Francia, The New Stack
Rust and Go are both relatively new languages that are being increasingly adopted by the research software development community. As is often the case in tech, there’s a lot of unproductive “X is better than Y” bickering among adherents.
In this article, a member of the rust team (Turner) and of the go team (Francia) come together and make it clear that the core teams of the two languages do not see each other as opponents, but rather complementary. They interviewed three companies (and others) who use both languages, and use quotes to indicate their points. This is a fun approach to such a blog post and one I haven’t seen before.
Turner and Francia point out that both languages are:
While the big differences are around learnability and fast iterations (go) vs fine-grained control, and rewarding long iterations with high performance (rust).
I’ve never really understood the rust vs golang arguments - they’re clearly aimed at disjoint use cases. Go is going to carve out a big swath of what had been Java’s domain - enterprise-type development, web services, or distributed systems (using static binaries rather than jar’s and JVM), having both garbage collection and opinionated build and dependency management setups - but it does all that with a nice small language and strong typing.
Rust is going to do real damage to C++’s “market share”, gaining adoption in systems programming or the building of individual tools where it makes sense to lovingly hand-craft the fastest code humanly possible - but will address those target uses with memory safety and without being weighted by 40 years of backwards-compatible baggage.
Both use cases are relevant in research computing. Both languages have enormous advantages over what they’ll end up displacing. But I have a really hard time imagining any intended application for which both languages would simultaneously be obvious contenders.
Accelerated Signal Processing with cuSignal - Adam Thompson, NVIDIA Developer’s Blog
It takes about 1/3 of the article before we learn the big news:
cuSignal GPU-accelerates the popular SciPy Signal library with CuPy (GPU-accelerated NumPy) and custom Numba CUDA kernels.
Obviously there have been CUDA packages relevant to signal processing for a while - for FFTs, sparse solvers, etc - but this allows researchers to, with some care, use scipy signal as an interface to code to and get GPU acceleration. And by using CuPy and Numba it allows zero-copy interfacing to tools like PyTorch for machine learning.
Why Dropbox’s Exascale Strategy is Long-Term, On-Prem, Disk - Nicole Hemsoth
Hemsoth writes another well-reported, interesting article - this time on Dropbox’s storage needs.
A lot - way too many - articles get written about compute and on-prem vs commercial cloud, but the much more interesting and nuanced discussions are around data and storage. Dropbox was an early adopter of AWS S3, but at its scale and for its use case, it’s sticking with on-premises:
“Cost isn’t number one, but it’s in the top three—and there are three things we look at when we make a decision about hardware. Is it more cost efficient to stay on prem or use the public cloud? We are operating at scale where customization is cost-efficient. And also, can we innovative faster than the public cloud? And further, is our workload unique compared to what the public cloud supports?”
Although I never really thought of it before this article, it makes a lot of sense. Dropbox is large enough that it is a hyperscaler itself of a (niche) sort - so buying servces from another hyperscaler doesn’t really make business sense for them. Having said that, Dropbox isn’t dogmatic about it - for some specialized workflows and for some international locations they do use commercial cloud services.
Maybe even more more interesting is that even though performance is important to the company, it is not moving to Flash or even SSDs in any big way; they see current and upcoming improvements in good-ol’ disk as being enough for their needs. Hemsoth has a nice summary (all new material to me) of emerging disk technologies looking out the next four years or so that makes Dropbox pretty happy with staying on spinning disk.
Practiced Humility in Retrospectives - Will Gallego
A nice article from a seasoned practitioner on retrospectives after an incident, and the importance of humility in running them.
One of the first humility lessons for Gallego was that he saw and ran successful retrospectives at Etsy - but when he went to another organization with different goals and culture it didn’t work. Other lessons included:
Goodbye, Minikube - Nicolas Fränkel
Using Podman and Docker Compose - Brent Baude
It’s a great sign the container-orchestration “market” is getting increasingly mature when people are writing “Goodbye, X”-type posts about early small-k8s distributions, or when alternatives to simpler solutions like docker + docker-compose come about.
Fränkel’s post talks about leaving minkube for the newer kind. Long-term readers will know that I’m pretty optimistic about various small kubernetii for at-the-edge type installations for some research computing applications - say complex applications that involve collecting and processing sensor data before sending it on. So news that that ecosystem is strengthening is good news.
In rootless-container news, Redhat’s podman now supports docker-compose, allowing for orchestration of these rootless containers - something that’s been lacking (at least with any robustness) with the singularity/podman type solutions. Since you still need root to run docker compose, wire up networks, etc, I’m not sure what the use case here is, though? Anyone know?
PRACE-ICEI CALLS FOR PROPOSALS - CALL #5 - Submission Deadline 16 April
PRACE’s call for proposals for resources on the EU federated Fenics infrastructure is out. EU researchers who need the following are eligible to apply:
On the evaluation of research software: the CDUR procedure - Dr. Teresa Gomez-Diaz, Prof. Tomas Recio, SORSE talk, 16 Mar 14:00UTC, Free
How do we evaluate if a research software development effort was successful? The authors will describe their method, looking at Citation, Dissemination, Use (usability), and (impact on) Research.
Building Research Software Communities: How to increase engagement in your community - Jeremy Cohen , Dr. Michelle Barker, Daniel Nüst, SORSE talk, 17 March 9-1 UTC, repeated at 18 March at the same time, free
A workshop on “building, developing, and sustaining research software communities”.
International Workshop on Performance Analysis of Machine Learning Systems - 28 March
One full day of meetings (9-5 Eastern US) on performance analsyis of AI/ML systems - covering workload characterization, acceleration of compute, memory, I/O and network, co-design, ML systems optimized for specific domain, and more.
Does a trainee or team member need to learn Git? Introduce them to Oh my Git!, the online strategy card came.
Continuing a recent recurring theme of the details of linkers and loaders - how to execute an object file if that’s all you’ve got.
We teach people to write code when they’re starting out but reading code is at least as important and scanadalously under-emphasized.
Internet Archive Scholar indexes 25 million open-access research articles and other scholarly items.
Advice on using conda in docker containers.
Netflix’s new workflow+serverless platform for e.g. video transcoding, Cosmos. This sort of platform could easily be useful for large scale production deployment of data analysis workflows as in genomics.
Has anyone played with dapr, which just reached 1.0, yet? It’s Microsoft’s multi-language microservices framework. It seems potentially useful but I don’t know anyone who has done anything with it.
Even after years doing this work, it’s always surprising how long “temporary” solutions last. MacOS’s “poof” animation was a placeholder that lasted for years.