jonathan@researchcomputingteams.org
In research computing, we’re always building at the cutting edge of something - whether that’s the technology, the use case, or the methods being implemented.
What part of a project is on the cutting edge will vary from effort to effort. It might be using well established methods and technologies but trying them out on a new problem (say applying existing statistical methods to data from new kinds of devices); it might be testing a new method for a familiar problem, using established technologies (trying emerging simulation techniques to get higher fidelity results in an area of fluid dynamics); or it might be trying to apply a completely new technology to a standard method for an existing problem to try to gain new capabilities (like the case of building cloud architectures for the analysis of archival wether simulations we saw on Friday, or taking advantage of NewSQL databases for curating field data in the environmental sciences). But something will always be new; implementing mature methods for well-understood problems on stable technology is enterprise IT, not research computing.
The ever-present novelty in our field has the big consequences - for the people needed, for the riskiness of each project, and for the lifecycle of each effort.
The first two are pretty straightforward. The first is for staffing a research computing problem: it is always going to require multidisciplinary expertise. You can’t make reliable progress on a research computing effort without expertise in domain science, methods, and technology.
The second is that the novelty inherent to research computing means that success of any individual attempt is much lower. That’s ok! Experiments don’t always turn out the way we hope, and we learn from each one anyway.
But the bigger consequence is to the lifecycle of the efforts. The ultimate goal for a research computing effort is to end; to hand off to someone else what had been a risky, novel exploration of a technique and has since become routine. A completely successful research computing evolves from itself being a research effort, to a research output, to a research input.
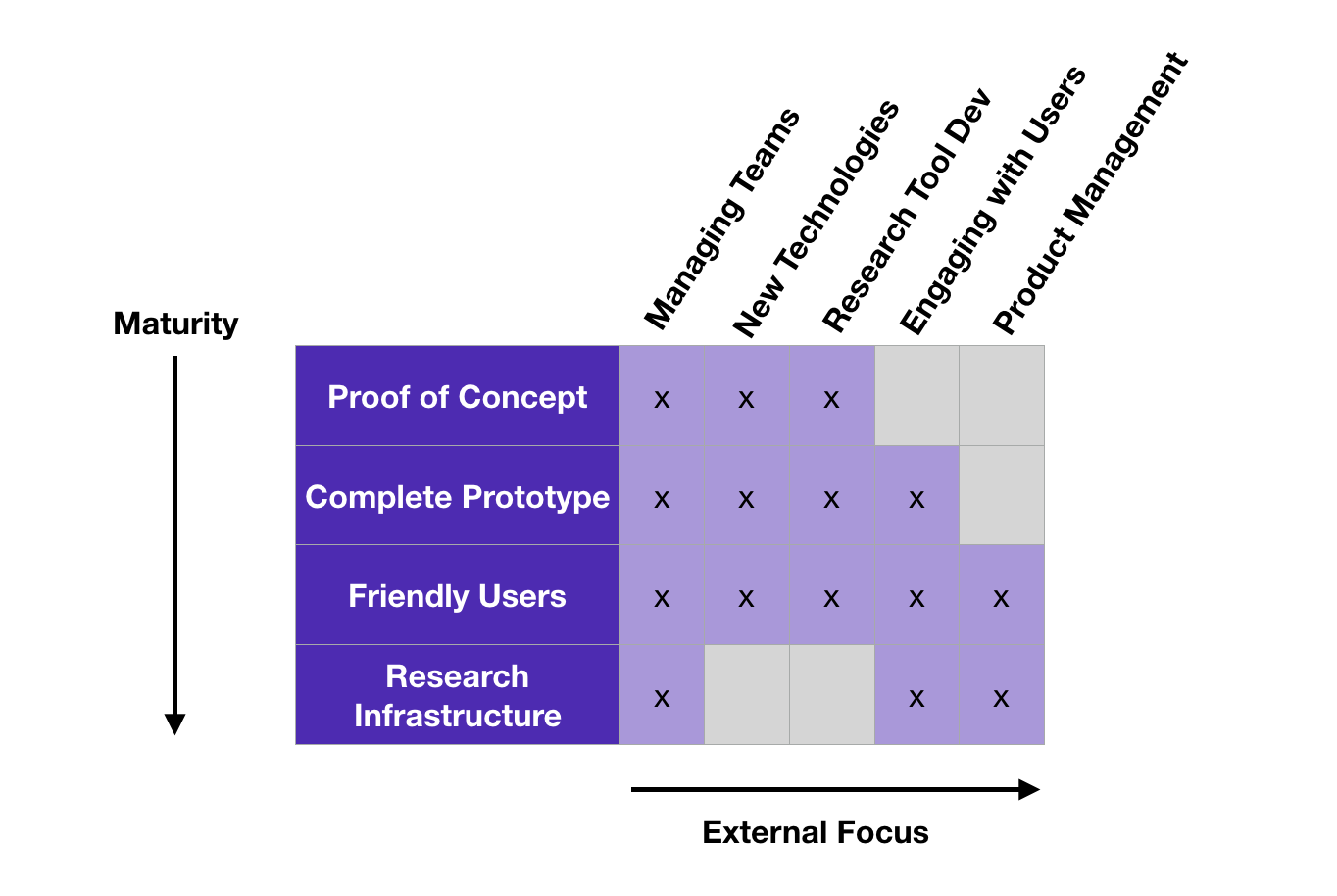
We achieve success in research computing by supporting large number of trials, and prioritizing and following up on the successful attempts. Initially there is a proof of concept, demonstrating some key germ of an idea. Successful proofs of concept can get built into a complete prototypes for an individual researcher, and if they work well they can be generalized and made robust enough to have other groups try to use it. If it helps those researchers enough that the tool starts to become widespread, it eventually becomes research infrastructure, where “research tool development” stops, and the routine maintenance of a mature product begins.
The above progression - PoC to prototype to something used by friendly users to something in production widely - can be thought of a simple, research computing specific version of the technology readiness model or capability maturity model. It’s a pretty familiar concept to our colleagues doing research computing work in the private sector, but we don’t usually think this way in more academic circles.
As the product matures, the work we do on it changes, and grows more outwardly focussed. We always have to manage effective research computing teams, successfully meeting our goals while developing our team members, but what they’re doing this time will grow with the product. In the earlier, more experimental phases there will be more exploring of technologies and less formality around development; as it begins to take shape there things will begin to change more slowly and have more rigour; there will be more outreach to user communities and prioritization of features.
Research computing really is a specific kind of R&D effort, turning research ideas and needs into stable products for researchers, and we can learn how to effectively manage those processes from other R&D teams - there are even conferences and journals and programs dedicated to the area. But we can also learn from ourselves about has and hasn’t worked for them and try to adopt those approaches.
Best,
Jonathan