jonathan@researchcomputingteams.org
Hi, everyone:
There were two big stories in the news this week about what’s possible with sustained research infrastructure funding and what happens when research infrastructure isn’t sustained.
In the first, you’ve probably read about AlphaFold, Google Brain’s efforts to bring deep learning to protein folding. It did very well in the 14th annual Critical Assessment of (protein) Structure Prediction (CASP) contest. Predictably but unfortunately, Google’s press releases wildly overhyped the results - “Protein Folding Solved”.
Most proteins fold very robustly in the chaotic environment of the cell, and so it’s expected that there should be complex features that predict how the proteins folded configurations look. We still don’t know anything about the model AlphaFold used - other than it did very well on these 100 proteins - or how it was trained. There are a lot of questions of how it will work with more poorly behaved proteins - a wrong confident prediction could be much worse than no prediction. But it did get very good results, and with a very small amount of computational time to actually make the predictions. That raises a lot of hope for the scope of near-term future advances.
But as Aled Edwards points out on twitter, the real story here is one of long term, multi-decadal, investment in research infrastructure including research data infrastructure by the structural biology community. The protein data bank was set up 50 years ago (!!); and a culture of data sharing of these laboriously solved protein structures was set up, with a norm of contributing to (and helping curate) the data bank. That databank has been continuously curated and maintained, new techniques developed, eventually leading to the massive database now on which methods can be trained and results compared.
It’s the sustained funding and support - monetarily but also in terms of aligning research incentives like credit - which built the PDB. The other big story we heard this week tells us that you can’t just fund a piece of infrastructure, walk away, and expect the result to be self-sustaining. On December 1st, the iconic Arecibo Radio Telescope in Puerto Rico collapsed. The telescope was considered important enough to keep running - there was no move to decommission it until late November - but not important enough to keep funding the maintenance to keep it functioning.

Digital research infrastructure - software, data resources, computing systems - fall apart at least as quickly without ongoing funded effort to maintain them. These digital pieces of infrastructure aren’t “sustainable” or not; they are sustained, or not. And too many critical pieces of our digital research infrastructure are not being sustained.
In the coming year, this newsletter will be spending some time giving research computing team managers the tools they need to make it as easy as possible for funders and adminstrators to make the right decisions and sustain our work.
For now, on to the link roundup!
The Power of Performance Reviews: Use This System to Become a Better Manager - Lenny Rachitsky, First Round Review
In one-on-ones, there should always be time to touch base on bigger picture items - career goals, finding out what your team members what to focus on, etc. But it’s good to have routine longer meetings taking a look back at the past months, and ahead to the next months, outside of the weekly cycle.
Since it’s end of year, there’s lots of management articles about annual performance reviews. I think both annual and performance are wrong here - annual is too seldom, and focussing on performance is a mistake. This is a good article on what’s good about this kind of meeting, though.
These can be really powerful ways to let your team members know what they’ve done that’s really valuable, to get aligned on what’s coming next, and talk about longer-term goals. In our own team we do them 3-4 times a year and I’ve found it works really well. We don’t rate performance or give scores - we look back on the past few months, note the team members accomplishments, compare them against the goals set, and then plan for the few months ahead. At least some team members quite like them and look forward to them - although initially there was some apprehension - and it’s a straightforward way to make sure you both have the same views about the future.
How to deprioritize tasks, projects, and plans (without feeling like you’re ‘throwing away’ your time and effort) - Jory MacKay, RescueTime
Focus is all about not doing things - which is tough in a research environment when there are so many interesting and valuable things that you could be doing! MacKay’s article summarizes some good strategies for not doing the right things.
Covid: Researchers fear cancer advances delay due to pandemic - BBC
A survey of more than 200 scientists at the Institute of Cancer Research suggested research could be delayed by six months, due to factors including the first lockdown and capacity limits
It’s worth emphasizing again that many of the researchers we support, even those who are who are doing pretty well now have fallen well behind where they would been. There may be opportunities to help them catch back up and take more of a collaborative role than just service oriented; and of those opportunities, some can be new services offered routinely in the future to other researchers.
Peer Review: Implementing a “publish, then review” model of publishing - Michael B Eisen et al., eLife
This is an exciting development - starting July 2021, the journal eLife will only consider manuscripts published as preprints for publication. Journal submission will mainly consist of a link to bioRxiv or medRxiv preprints. As part of review, reviews will also be published when the article is published.
Software-based targeted nanopore sequencing with UNCALLED - Sam Kovaka, Nature Bioengineering Behind The Paper
Targeted nanopore sequencing by real-time mapping of raw electrical signal with UNCALLED - Sam Kovaka, Yunfan Fan, Bohan Ni, Winston Timp & Michael C. Schatz
A nice story about how a class project turned into a first-author paper for PhD student Sam Kovaka - involving real-time analysis of data coming out from an Oxford Nanopore sequencer allowing selective sequencing - the nanopore can “spit out” sequences that have been rejected. This allows the sequencer to focus just on the sequences of interest - i.e. one kind of bacteria or not another, or even panels of human genes.
It’s really nice work combining signal processing, string data structures, and even writing a data simulator.
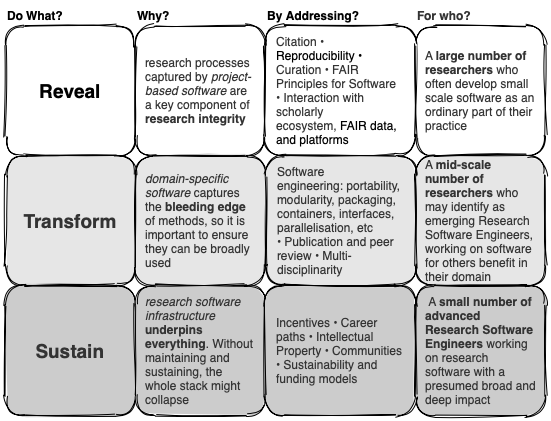
High level overview of how Australian Research Data Commons is viewing Research Software as a First Class Object - Tom Honeyman on Twitter
This is a really interesting diagram of how ARDC is thinking of research software:
Here's a preview of what we're thinking (high level) for a national agenda for #researchsoftware as a first class object @ARDC_AU. Feedback welcome pic.twitter.com/XtfwhK48DN
— Tom Honeyman (@TomHoneyman3) November 30, 2020
The approach is I think the right one, and one I’ve advocated before; taking a path-to-maturity model approach, where the levels are (in their terms, with my interpretations):
I think of this as “proof of concept; prototype; production”. They’re very different stages. More controversially, I think of only the first, proof of concept, as actually being a research output; prototype and production are about turning that research output into a research input.
How to Make Your Code Reviewer Fall in Love with You - Michael Lynch
A nice article outlining how to write PRs to make them as easy review as possible - making them easier to approve. Good for individuals working on open source projects and for teams working together.
There are 13 steps there, but several I think deserve calling out:
Bringing software to the limelight in the Research Data Alliance - Software Heritage
One of the themes of this newsletter is that research computing systems, research software, and research data management are inextricably intertwined. While individual teams obviously focus on one part of the ecosystem, looking funding, policy, or staffing at any higher level, even within an institution or faculty just can’t succeed long term if it’s considering the different components individually.
This is an example of how organizations with quite different focuses are working together to provide more of that integrated view. Research data is increasingly preserved with the scripts needed to analyze and process the data; but the metadata needs for discovery and reusability of software are different than those of data. So the Software Heritage organization is working increasingly closely with the Research Data Alliance to connect those dots.
How to apologize for server outages and keep users happy - Adam Fowler, Tech Target
When AWS has an outage, it’s in the news and they publish public retrospectives (and here’s a great blog post of the retrospective of the Kinesis incident this week).
Our downtimes and failures don’t make the news, but we owe at least that same level of transparency and communication to our researchers. The technical details will differ from case to case. But what’s also needed is an apology, and some clear message that the team has learned something from the outage to make it less likely to recur. Fowler outlines what’s needed for such an apology:
From experimental software to research infrastructure maturity - 7 Dec 14:30 – 15:00 UTC, SORSE Talk, Carsten Thiel
In issue 49 we talked about the EOSC maturity checklist for software to be installed on the EOSC cloud; this talk by Theil covers the “why” of this approach and gives more details about the “what”.
HPC for Data Science video lecture series - Support session Monday 14 Dec; Warwick University
Because of COVID, this lecture series is not only online but asynchronous and work-at-your-own-pace; but there is a support session where you can get help. There’s a nice mix of videos, PDF notes, and exercises. This mix of at-your-own-pace and video synchronous office hours could be a very useful model for other groups.
A very efficient compressed read-only file system for data with significant redundancy - dwarfs.
It’s not a super common use case, but if you’re supporting research groups which are actively curating a dataset and who want to be able to review changes, roll back, etc, there are several “databases, but with git-like version control” out there now that may be of interest. This New Stack article discusses TerminusDB, Dolt, and and others.
Really cool to see AWS’s Scalable Reliable Datagram for Elastic Fabric Adaptor - high performance low-latency network communications - first publicly rolled out for HPC use cases, now being used to connect high-IO nodes to EBS volumes.
A talk extolling the virtues of a text-based markup format for publishing that’s ubiquitous in tech - even though it’s a little old now, nothing’s ever really surpassed it. I’m speaking, of course, about troff.
Everyone’s heard about this by now - Mac minis on AWS (not the M1s yet). What’s cool is they use AWS’s nitro, so you have bare metal access but can still, e.g., mount EBS volumes.
A comprehensive guide to bash parameter substitution - including default handling, pattern removal, find/replace, etc.
Finally, a gopher browser for the Nintendo Switch.
More reasons than you expect that SELECT * is bad for performance.