jonathan@researchcomputingteams.org
Hi there - if this is a long weekend for you, I hope you’re enjoying it.
Last time we spoke a little bit about expectations, and routine feedback to team members and peers when those expectations are met or not met. This time, let’s consider - or skip to the roundup.
Feedback is a mechanism to align expectations with your team members in the moment, and to encourage meeting those expectations in the future. Sometimes those expectations were explicit; other times, they were implicit and it’s a helpful way of making them explicit. This is a simple, extremely useful and scandalously underused tool, particularly in research environments. What’s more, your team members want feedback. Do you want more feedback from your manager about how you’re doing? Why do you think your team members feel differently than you do?
On top of the small course-corrections of routine feedback, it’s important to have regular conversations looking back at previous goals, and setting future goals. Here, the expectations are very explicit - you are setting goals, and looking back to see if they’re set.
Our research institutions probably have an annual review process set up for this. They’re usually incredibly poor. What’s more, a year is just an absurdly long time in research computing to set goals. For most of us, our work is changing rapidly; the idea that today we should have a pretty good idea of our work from now until April 2022 is just goofy.
Quarterly is a pretty good cadence to review work, learning, and career development goals with team members. Twelve-ish weeks is long enough to accomplish meaningful work, while being short enough that priorities probably haven’t shifted dramatically in the intervening time. These goals are things you absolutely can and should be talking about in one-on-ones, but setting some time aside every quarter just to have these goal-review and goal-setting conversations helps clarify expectations about goals, ends up with them written down, and gives team members clarity about what their priorities are. The resulting document is also something that can inform one-on-one discussions.
A template for the document I use for such reviews is available as a google doc here; I show an excerpt below. By having it as a google doc (or Office 365/sharepoint document, or whatever tools your team use routinely), it can be kept as a running document (most recent review on top), collaborated on, and frequently reviewed. What will be most useful for you and your team may well be different. I use these reviews as an occasion for a bit of a deeper check-in on how things are going in areas that sometimes get overlooked in the more day-to-day focus of one-on-ones.

The mechanics of these reviews is that we schedule a meeting outside of our usual one-on-ones; an hour is generally enough for a team member whose done this before, it might take more than that for a team member doing it the first time. I update the document by adding the review for the new quarter, taking goals set last review and copying them in; then each of us adds starting notes. The document covers:
The meeting then discusses the starting notes from myself and the team member, and then agree to summaries and commit to future goals. Having their input on these sections is extremely valuable; it increases the commitment to the goals.
The first time a team member goes through this, it can be a little scary - people have had or heard of pretty terrible performance review experiences in the past, and they often don’t realize it’s an opportunity for a conversation about what’s going well, what haven’t, what priorities to work on, and their own learning and career development goals. To make it a little less difficult to start this the first time, when onboarding a new hire we immediately set 30 day goals in the worksheet, then after a month set goals for the remaining 60 days of the quarter. At the end of their first quarter we go through the sheet together for the first time, but it’s at least partially familiar to them so doesn’t seem so daunting.
Do you have a similar process? Have you seen anything similar or that you find works very well? Let me know - hit reply, or email jonathan@researchcomputingteams.org.
For now, on to the roundup!
The resilience of mixed seniority engineering teams - Tito Sarrionandia
An ongoing if unintended theme of the newsletter is that when managing teams, many useful things - like everything involved in having the team move to distributed work-from-home, giving feedback, having quarterly goal-setting - come down to making things more explicit. That requires a lot of up front work, more documentation, change of processes, and a little more discomfort for the manager initially - but then make a lot of other things better and easier for everyone.
Sarrionandia talks in this short article about the advantage of having teams with a range of seniority in exactly this light. Having junior staff on the team means that more resources have to be dedicated initially to explaining how things work, documenting processes and tools, etc. But those steps of making things more explicit make things work better for everyone. It makes it easier to bring new people onto the project, junior or senior. Those now explicit steps can be put into playbooks or automation scripts (or conference talks, or papers). More work initially, but that work pays off.
Measures of engineering impact - Will Larson
I’ve mentioned before that as a manager, we measure something to inform a decision or action. We’ve talked about measuring the productivity of technical teams - you have to look at the team level, not the individual, and pick metrics that indicate something getting in the teams way, something that you can change. The measures inform an action. That’s useful; you can arrange for fewer things to be in your teams way.
But measuring the impact of the technical teams is really what we want to accomplish. You want your organization to have as much impact as possible. We owe our team members work with meaningful consequences, and we owe the research endeavour as much help in the advance of knowledge as we can offer.
Larson and some of his colleagues discussed this and found that a number of big tech companies have almost comically simple measures used internally for impact, that are straightforward, centre on the things they care about, and are hard to game:
As people working in scholarly research, one of the skills we’ve developed is ways to disprove or provide evidence for the claim “X affects Y” by choosing one or more proxy measurable quantities to observe. This is one of our outsized skills. Choosing simple metrics can be a very effective way of demonstrating impact externally and informing decision making internally.
In research computing, some of our measures take some doing but are inarguably signs of impact - amount of use, papers published, citations, contributions. Which ones make the most sense will depend on what your teams work on; but any of them or any related metric is 100x more meaningful that input measures like utilization, lines of code, or data entries.
One mentor isn’t enough. Here’s how I built a network of mentors - Erika Moore
We’ve talked about assembling a group of mentors before, such as in #60. People by and large are more than happy to give advice and suggestions to others coming up in their field. Here Moore, writing in Science’s careers section, gives very specific and useful steps about how to build a network of people that one can ask for advice:
Writing in the Sciences (Coursera Course) - Kristin Sainani
Writing is one of those things that many of us got into science or computing to avoid. But written communication, especially to stakeholders and the public, is vital for effective product management in research computing. Sainani has what looks like a pretty good short course on writing for within research communities and to the public:
Topics include: principles of good writing, tricks for writing faster and with less anxiety, the format of a scientific manuscript, peer review, grant writing, ethical issues in scientific publication, and writing for general audiences.
Product Manager Assessment - Sean Sullivan, ProductFix
In research, we typically learn on the job a rough-and-ready form of project management, which can work passably well for research projects.
In managing research computing teams, though (and arguably when you’re running a large enough programme in research) our primary focus is on managing products - software, data, systems, expertise - not projects. This is one of the reasons why research funding, invariably project based, is such an awkward match for research computing. We may very well execute projects as part of our product management, but the product as a whole outlasts any particular project.
In this article, Sullivan walks through a product management assessment with three high-level components - product expertise (including product/market fit), product management and skills (shown below), and people skills and other competencies.
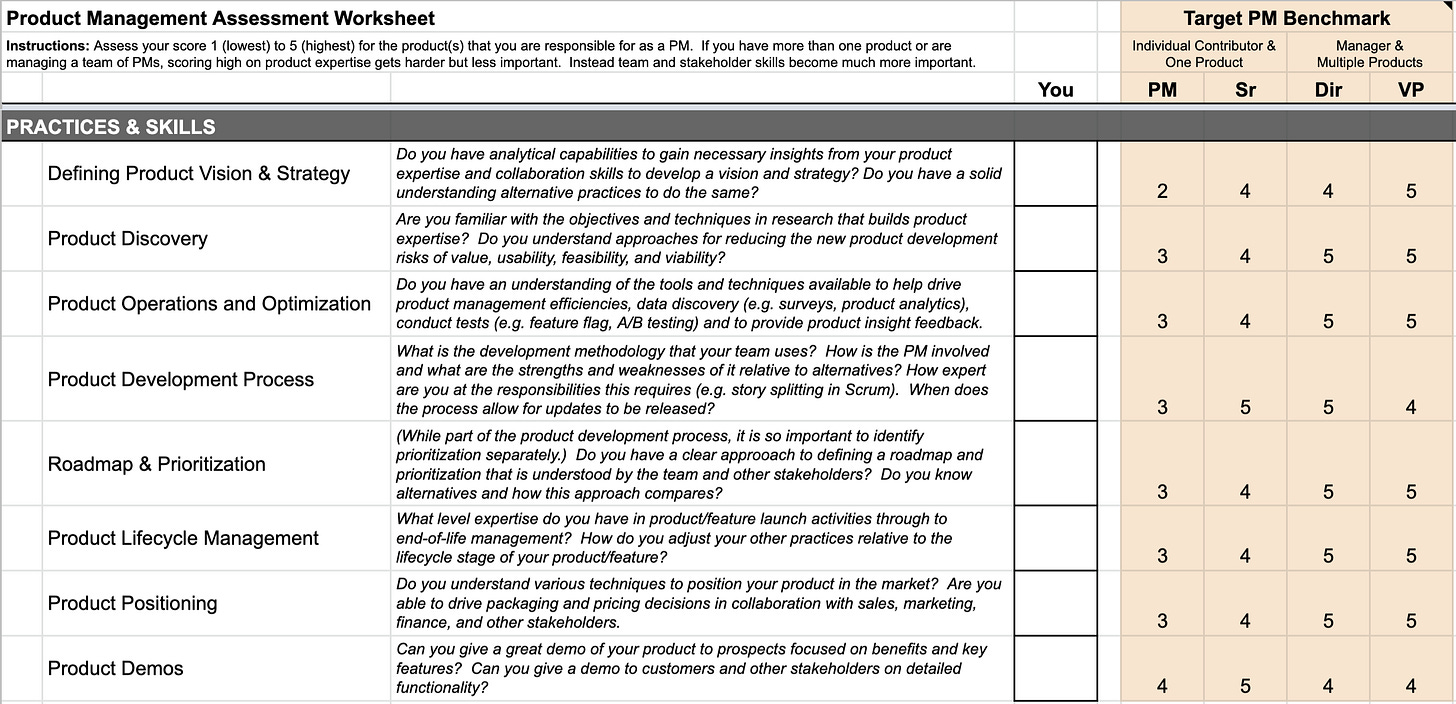
I think this would have to be changed quite a bit for the research computing context - what getting money for our products looks like in research is very different than in the private sector. But in terms of illustrating the breadth of needed skills, and areas to be aware of when managing multiple products, I think this caries over into our world.
What do you think - what skills would a very capable research computing product manager have?
Why Do Interviewers Ask Linked List Questions? - Hillel Wayne
In a field that values moving fast as much as software development, where the worst thing you can say about a piece of code is that it’s “legacy”, it’s surprising how many practices persist “because that’s the way it’s always been done”.
In this article, Wayne looks into why linked list questions are so common in software development interviews. It’s been that way since the late 70’s to mid-80s. And Wayne’s proposed explanation makes sense - it was basically fizz-buzz for having written programs with non-trivial data structures in C or Pascal (the 2nd most common language at the time) - languages with pointers but without any real standard library of data structures, so you had to roll your own.
About the Open Source Security Foundation - the OpenSSF
With open source software and dependencies, we’re building on the shoulders of giants - but what if some of those giants are malicious?
There’s been a lot of justified concern about open source software supply chain attacks with malicious or compromised dependencies. The OpenSSF is trying to build a community around security tooling, best practices, vulnerability disclosures, and identity attestation for OSS dependencies. Good to know about, and potentially get involved with.
The Zero-prep Postmortem: How to run your first incident postmortem with no preparation - Jonathan Hall
It’s never too late to start running postmortems on your systems when something goes wrong. It doesn’t have to be an advanced practice, or super complicated. Hall provides a script for your first couple.
I’d suggest that once you have the basic approach down, move away from “root causes” and “mitigations” and more towards “lessons learned’. Those lessons learned can be about the postmortem process itself, too; you can quickly start tailoring it for your team and work.
socat - Cindy Sridharan
Sridharan provides a nice introduction to socat - kind of like netcat but much more flexible - any network or unix domain socket (datagram or stream), file descriptor, sctp, pty, named or unnamed pipes, openssl… Very useful for debugging , testing, or for quickly doing ad-hoc data movement between different kinds of linux processes.
BPF for storage: an exokernel-inspired approach - Yu Jian Wu et al., arXiv
Introducing Amazon S3 Object Lambda – Use Your Code to Process Data as It Is Being Retrieved from S3 - Danilo Poccia, AWS News Blog
Moving processing to the data is increasingly important; these two very recent items describe two very different approaches to it.
In the first article, the authors push some data processing into the kernel, via eBPF. The paper takes inspiration from the networking community, which has long done offloading of some simple processing to the network card or the network stack; as well as exo kernel file systems from the late 90s. Having some of the processing of data happen in the kernel can reduce the number of user-kernel context switches and data boundary crossings. They implement on-disk B+ tree lookup in kernel with eBPF (!) and find that latency can drop by half and IOPS by even more.
In the release by the AWS S3 team, Poccia describes combining lambda functions and S3 access points to automatically process data pulled by S3 buckets. This could support processing of data near the S3 bucket, but also can provide features such as redaction of data, providing “views” of data in different formats, augmenting data with information from other sources, etc.
ACM SIGHPC Computational & Data Science Fellowships - Nominations close 30 April
May be of interest for trainees you work with; nominations are now open for this $15,000 USD fellowship (or purchasing power equivalent in other countries). Eligible are graduate students (masters or PhD) early in their program.
4th International Workshop on Practical Reproducible Evaluation of Systems - Papers due 20 April; workshop 24 June
As part of the virtual ACM High-Performance Parallel and Distributed Computing 2021 meeting, this workshop focusses on automated and reproducible computational experiments for evaluating computational experiments - simulations, evaluations of systems, etc.
The 3rd International Workshop on Parallel Programming Models in High-Performance Cloud (ParaMo 2021) - 10-12 page papers due 7 May; workshop Aug 30-31
This workshop, held as part of Euro-Par 2021, focuses on high performance computing in the cloud - including programming models, frameworks, network storage and memory management, heterogenous resource management, performance evaluation and configuration.
Workshop on MAthematical performance Modeling and Analysis (MAMA) - Papers due 17 May; Workshop June 14
Performance analysis, modelling, and and optimization is the topic of this 1-day workshop held as part of the virtual ACM SIGMETRICS 2021.
Developer First Tech Leadership Conference - 6 May 2021, $5-$50
This day-long conference has talks covering people management, asynchronous and remote development, managing technical assets, running effective meetings, dev team metrics that matter, and managing your own time.
May HPC User Forum Meeting, 11-13 May North America friendly timezone, 12-14 May Europe/Asia friendly timezone
A three day virtual HPC User Forum meeting, free for members.
Something that may be useful for your team or researchers you support who work with data in python - a pandas drop-in replacement that runs in parallel using Ray or Dask.
A bracing, curse-laden reminder that there’s no best programming language, and no one other than contributors should really care what language you use.
A free and open-source online whiteboard tool. Not as feature-packed as say miro but very easy to get started with.
Quickly show some mathematics on your screen (for say a video call) with markdown, latex, and muboard.
Characters that work well across platforms and terminals.
WebGL is one of multiple ways of having performant visualization tools in the browser. There’s a new generation of WebGL, WebGL2, but most tutorials either haven’t kept up or have lazily updated WebGL1 resources. This is a nice looking tutorial of WebGL2 from scratch.