jonathan@researchcomputingteams.org
Hi, everyone:
I hope you’ve been well; I’ve had a short week with a 4-day Easter long weekend. Between being recharged for the weekend, and finally having a couple of days of work where I could focus on high-leverage activities - hiring discussions for our team and pushing forward a hiring process at an organizational level; writing a document useful in itself but also that will be a model for team members to write others in the future; getting two teams aligned and getting them to find a really good solution to a shared design problem - it’s been a really good week.
It took me a long time to re-orient myself to understanding what “a good day’s work” looks like for a manager. Everything is so much more direct and quicker-feedback as an individual contributor; the thing works or it doesn’t. As a manager, quick wins are few and far between - and you can only be really sure you made the right decision months after making it. So having two or three good managerial days in a row is a nice feeling and a good way to wind down a week.
I hope you’re having similar success.
And now, on to the roundup.
10 Stage Guide to Planning Your Return - Bruce Daisley, Make Work Better
At some point, the pandemic will be over and we’ll all be deciding what to do about the workplace. I think the most successful research computing teams will remain mostly distributed - and will in fact become more distributed as they start to hire new far-flung team members. But it’s not entirely up to all of us, and even those who stay largely WFH will probably want to come into the office together occasionally.
Daisley goes through ten steps in figuring out what “return” should look like. He lays out five nice clear things that “the office” did for us before:
Some of these we now have pretty clear ways of dealing with without an office, but I think there’s areas where we’re still trying to figure things out. We have figured out 1 outside the office, and mostly 3 (although in-person white boarding is really powerful). Some teams are doing pretty well with 4, some aren’t. 2 and 5 I think most of us are still struggling with - especially teaching junior hires.
With those laid out, Daisley advocates for an experimental approach - find out what people’s needs are, propose experiments (with clear measures of success), and try them.
Research: How to Get Better at Killing Bad Projects - Ronald Klingebiel, HBR
As we talked about at the start of the year, it’s hard to stop doing things, even when they don’t make sense any more. As Klingebiel reports, even big companies with well-established stage gate processes for advancing projects are tempted to fudge the requirements to let struggling projects advance and take up more resources - especially when the requirements that are struggling are (the more important!) external user requirements which are about the future and nebulous users, as opposed to the very salient internal struggles like technical difficulty.
To avoid the problems seen by Sony Ericsson in this study, Klingebiel recommends:
Common management failures in developing individual contributors - Camille Fournier
Fournier writes about some common ways that managers - especially new managers but I’d argue it’s quite common even in more experienced managers - fail to develop the skills of their team members. While we’ll often make time for a team member to learn some new framework or to read some papers in a new area, building them up in their technical/product leadership ability is more rare. Not only is this a wasted growth opportunity for the team members, it’s an good and important way for you to make time to grow your own skills in delegation - and then to be able to take on other responsibilities!
Fournier calls out five areas she sees that technical managers don’t take the opportunity to grow their ICs, and describes each very well in the article:
All of these are very relevant in our field, but I think this quote below on feedback is especially true in research:
Many new managers are comfortable giving technical feedback and uncomfortable giving other kinds of feedback. They freely criticize the design and technical work of their team, but they don’t challenge their team members on other growth areas like collaboration, communication style, or project ownership.
Launching ML4AU – a machine learning community of practice for Australia - Australia Research Data Commons
An interesting effort out of Australia - ML4AU is an attempt to bootstrap a national academic ML community of practice. The effort includes ARDC, Monash, University of Queensland, NCI Australia and Pawsey, They have a series of events (but, unhelpfully, not all are public - Monash seems to want to keep many of the events to themselves), some train-the-trainer materials and resources. I hope this succeeds and there’s good stuff here but this seems to be well short of the critical mass necessary to start a distributed national community of practice.
Those pesky pull request reviews - Jessica Joy Kerr
Can pair programming replace code review? - Jonathan Hall
Kerr’s blog post in late March kicked off a series of posts in the software-dev blogosphere on whether we should still be doing pull reviews. There’s too many posts to list here, but these two by RCT roundup regulars, cover much of the range of views.
Kerr’s pretty firmly on team get-rid-of-’em. My summary of her argument: There’s a reason why no one likes getting or giving pull request reviews. They are hard to do (because you have to load all the context of the person making the change into your head, then review the code, then come up with the review), can be unpleasant to get. They’re inspired by the open-source github pull request model, taking untrusted code from strangers on the internet, where it works well and is necessary, but is that really a helpful model for a software development team? Let’s get rid of PRs and do pair programming instead - it provides the same key functionality (knowledge dissemination to another team member and second person’s overview of the code) without the low-trust structure. Quoting her pull-quote:
Pull requests are an improvement on working alone. But not on working together.
Hall is on team keep-’em; while he likes pair review for mentoring and for encouraging deep understanding of the code by another team member, the higher-quality of code review (by someone coming to it in the cold light of day) and the higher-quality of written documentation in the PR (meaning everyone, not just the pair involved, can see the reasoning behind the change).
One thing I’ve really enjoyed about this conversation has been a lot of thoughtful discussion (including by these two authors) about the why’s of code review. Myself, I’ve been pretty influenced by Chelsea Troy’s articles about PRs as asynchronous pair programming, and if we’re going to increasingly have distributed flexible teams - even more so if we’re going to have community research software accepting external contributions - I think we’re going to have to have PRs. That doesn’t rule out synchronous pair programming, though; I think it compliments it.
Working in a National Lab vs. Academia - Vanessa S.
Academia is a very.. particular kind of work environment, and institutional support for software development in research is pretty new and haphazard. In this article, the author describes the difference of working at Stanford as an RSE and running an RSE team there, and as a Computer Scientist at Lawrence Livermore National Lab.
As the title already suggests, research computing is taken much more seriously in the national labs, and has been for (at least) couple of decades. Pushing forward significant advances in computing infrastructure tools is a goal in and of itself there allowing for a longer-term focus on technological advancement rather just focusing on whatever professor so-and-so wrote a grant for last year.
It’s a good and comprehensive long read if you are interested in the comparison.
Examining Problematic Memory in C/C++ Applications with BPF, perf, and Memcheck - Filip Busic, Doordash
Some computing problems are truly universal - even so, it’s weird to see modern tech companies writing posts describing tools that I used to write documentation for at my research computing centre years ago.
In this article, Busic walks through tracking memory issues with the venerable valgrind memcheck, and then adds newer tools like BPF and perf. To use those lower level tools, more knowledge is necessary, so he gives a crash course on Linux’s memory model, stack unwinding techniques, and tracing event sources, and then describes using perf (née perf_events) and BPF to track memory events in the system.
Understanding CPU Architecture And Performance Using LIKWID - Pramod Kumbhar
Kumbhar starts his article with a short but broad overview of current processor microarchitecture. He then gives a detailed overview of the capabilities of LIKWID, a new-to-me set of tools developed over several years at Erlangen Regional Computing Center. It looks to be a swiss-army-knife set of tools that allows understanding the topology of a node (threads, cores, sockets, caches), thread affinity domains, and pinning; for performing microbenchmarks on memory, flops, and cache; studying numa effects; setting cpu frequencies; measuring power consumption; and monitoring performance counters.
AAIB investigation to Boeing 737-8K5, G-TAWG 21 July 2020 - UK Air Accident Investigation Branch
[…] when a female passenger checked in for the flight and used or was given the title ‘Miss’, the system checked her in as a child. The system allocated them a child’s standard weight of 35 kg as opposed to the correct female standard weight of 69 kg. Consequently, with 38 females checked in incorrectly and misidentified as children, the G-TAWG takeoff mass from the load sheet was 1,244 kg below the actual mass of the aircraft.
If you want to see incident reports and postmortems done right, then aviation - which has been doing this for a long time - is always a good choice. Check this one out. There’s a clear technological “root cause” - the software was programmed in a jurisdiction which made clear distinctions between Miss (used for children) and Ms (for adults) and used in a country where it wasn’t, resulting in the takeoff mass of the plane being one and a quarter tonnes off. But the report doesn’t stop at that. Why didn’t the pilot notice there was a really weird number of children listed? Why couldn’t ground staff update the numbers? Why did no one know about this? How did this not show up in testing? What can we learn from this to avoid not just this but similar incidents in the future?
The PDF is a short read and well worth it for a great example of an incident report. And note the tone - everyone was doing their job, it’s no one person’s fault, but something unacceptable happened and we need to make changes so this doesn’t happen again.
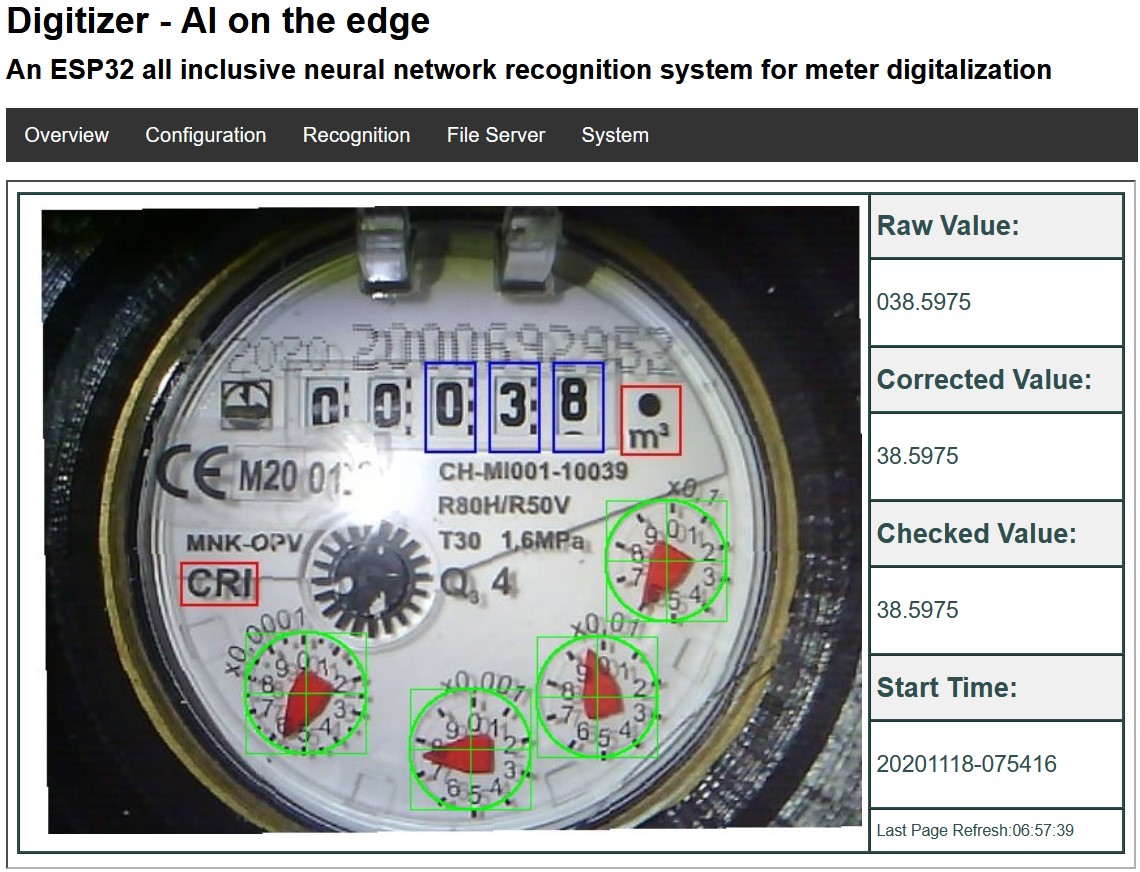
How screen scraping and TinyML can turn any dial into an API - Pete Warden
I’ve mentioned before my hopes for internet-of-things type connected devices to enable easier, timelier large-scale data collection for some research purposes. But a lot of experiments have a lot of devices out there already that are decidedly not smart-devices; what to do with them?
Increasingly smart edge devices and tiny-ML frameworks like TensorFlow-lite make it possible to brute-force this by simply using pre-trained models to infer device readings directly. Warden points out a pretty cool ES32-based experiment with source code for doing exactly such a thing.
Introducing support for per-job Amazon EFS volumes in AWS Batch - Angel Pizarro, AWS HPC Blog
Something that I find dishearting is seeing research computing teams trial adoption of a commercial cloud service by mechanically, faithfully reproducing every detail of their on-premises system - where tradeoffs were made that might be reasonable in that context but make no sense at all in a cloud environment. The most mystifying such design “decision” I see being made is creating a single large Lustre (or moral equivalent) system for all possible users, just like in their machine room. But… why? I understand why that’s a reasonable choice for static infrastructure, but even there a large shared file system is n never-ending source of pain and anguish. Why would someone replicate that in an environment where one can spin up and down filesystems and attach them to instances at will?
In one of the first posts to the new AWS HPC Blog, Pizarro talks about a new feature which takes that flexibility to an extreme - in AWS batch jobs, you can now automatically spin up ephemeral elastic file systems per job, allowing a job to generate output (or stage in inputs) to a fast POSIX file system, and then stage it out when done, for each job, minimizing the amount of time being spent maintaining or paying for such file systems.
Computing Innovation Fellows - Applications due May 2021
From the website:
Similar to last year, the CIFellows 2021 awardees will receive a two year postdoctoral opportunity in computing, with cohort activities to support career development and community building. Realizing there are still many unknowns with the pandemic and that situations are different across the nation, there will be some flexibility in the program. Applicants must coordinate with one or more proposed mentors to create a Research Plan, Fellowship Plan and Mentoring Plan. We encourage community members to use their networks to find potential matches. To help with this process, we have created an Opportunity Board for the CIFellows 2021 application cycle
NVIDIA GTC ’21 - April 12-16, Through the day Pacific Time, Free registration
NVIDIA’s GTC this year snuck up on me. As always there’s a million sessions, and with free registration for the main part of the conference, this is sort of a no-brainer if the times work for you.
Some free sessions of interest to RCT newsletter readers include - update on NVIDIA HPC libraries and software, deploying inference servers, upcoming CUDA releases, Keras/Tensorflow roadmaps and a PyTorch update, NLP for cancer data, new dev tools, performance optimization, and a lot more. There are also full day workshops for around $249 on hands-on introduction to deep learning and other topics.
Workshop on Graphical User Interfaces for Research Software - 27-29 April, UK time, Free registration
Having a workable GUI, if done right, can significantly increase the usability of some research software. This free three-day workshop - including the final hack-day - introduces the basics of interface design, some GUI frameworks and patterns, methods for testing GUIs, and then has attendees work on developing GUIs to existing tools.
I don’t think I realized that tmux let you move cursors around to copy-and-paste text with your keyboard.
A list of 9 use cases for debugging with strace.
Chezmoi, a secure distributed dot-file manager.
Almost any website framework can be a static generation tool - with some help from wget.
In research computing we often have to get started with unfamiliar code. This is a good worked example of someone demonstrating how they started working with a new codebase - nginx.
With modern technologies available to us like Webassembly and Rust, we can do all sorts of completely new… aw heck, let’s write a telnet chat client.
The tiobe top-20 most popular programming languages list has a “new” entry this month - Fortran.
Nice conceptual overview of networking in kubernetes.