jonathan@researchcomputingteams.org
Hi, everyone:
Thanks for your comments about earlier hiring and feedback posts. I’m taking those responses and getting some help pulling those together, incorporating the input, adding more material, and putting into some kinds of coherent wholes that can be made more widely available (like the getting started with one-on-ones material). As always, I appreciate your comments, questions, suggestions, and feedback - please always feel free to hit reply or email me at jonathan@researchcomputingteams.org at any time.
For now, the roundup!
Why a Positive Offboarding Experience Matters More Than Ever - NOBL
It’s not personal, but once the pandemic is over and some kind of normalcy returns, a lot of people are going to leave their jobs. The past year has been stressful and exhausting, and even if their job wasn’t a big part of that, a lot of team members are just tired with everything and are going to be looking for a change.
So while it’s always good to be prepared for any given team member to leave (make sure everything’s always documented, use one-on-ones to have a good understanding of what everyone’s working on, use techniques like pair programming/PR reviews or talks and demos to disseminate knowledge), we should be doubly prepared in the coming months.
The post on NOBL makes the following suggestions:
It may seem odd to celebrate the team member leaving, but basically none of your team members are going to keep their current job with you until retirement. They will all move on, and new team members will join in their place, that’s good and healthy, and we want to mark these moments like all life transitions - celebratory, even if a little melancholy.
To the list they provided, I’d add: make sure you have the documents - job description, evaluation framework, interview questions - in place to be able to post a job ad for a replacement for anyone on a moment’s notice. (If you don’t - review the hiring discussion we had in #59, #60, #61) .
Embrace the Grind - Jacob Kaplan-Moss
The most powerful tool in my facilitation arsenal - TestSheep
These two articles point out the power of fairly simple (but tough to do) behaviours to move projects or conversations forward.
In the first, Kaplan-Moss tells us about the power of just sitting down and grinding through a lot of manual work to make a big impact. The work example hs cites is simply spending the hours of time needed to go through a huge issue backlog, categorizing and labelling and prioritizing. With that done, the team was now unblocked on closing a number of the tickets as duplicates, seeing the patterns in what needed to be done, focussing on the highest value issues, and plowing through the backlog.
I’ve noticed this too in my own career - sometimes just bearing down and doing a bunch of unglamorous manual work can shift project momentum in ways it needs to go, or bring you to the table for conversations because you now have produced something of value that wasn’t achievable another way.
In the second article, the author points out the power of just staying silent when facilitating conversations. This is especially important to us as managers with some authority. Being silent for what feels to you an incredibly long time will eventually prompt others to contribute.
Dirty Escalations: Making Frenemies and Pissing Off People - Chase Seibert
So Manager-Tools would tell us, correctly, that escalation is a very broad term that means any kind of communication of increased urgency/importance - bringing a due-date of a deliverable earlier, going from an email to a phone call or a quick video chat, etc. That is all true, and “escalation” is also widely used to mean specifically raising an issue up the organizational ladder, and until we have a term specifically for that kind of activity, people will continue to use escalation to mostly mean that.
Seibert talks about the “to the manager” kind of escalation, what the problems are, and how it can go bad. The suggestion is to have the two team members jointly escalate to their manager(s) with a co-authored document which then maintains the context as it goes up the chain. Not only is that a pretty good approach, it even works when the team members share a manager and that manager’s you. You want to avoid being the tie breaker of first resort, and encouraging your team members to author something and send it to you is a good step towards having them get it mostly sorted themselves.
Ramadan Mubarak! - Ramadan Tips for Non-Muslim Friends of Muslims - Fahmida Kamali
Ramadan is here, and Kamali offers some tips for those of us who are non-Muslims to be supportive to and non-weird around their Muslim colleagues during this period of fasting. As Kamali points out in a twitter thread, working from home does not make it easier to fast (do you find yourself eating less these days?) and we could all use a little extra support right now. In this slide deck, she offers some background and some tips:
Expasy, the Swiss Bioinformatics Resource Portal, as designed by its users - Séverine Duvaud, Chiara Gabella, Frédérique Lisacek, Heinz Stockinger, Vassilios Ioannidis, and Christine Durinx, Nucleic Acids Research
It’s fair to suggest that for a lot of research computing product development, feedback from users comes towards the end of the process. With the re-design of Expasy, the Swiss Institute for BIoinformatics’ bioinformatics resource portal, the developers used a more tech-industry style of user input, doing a usability assessment study of their existing portal (one of the first 150 websites in the world!), looked at existing user flows, and looked at competitors. Then they proposed some broad approaches to key stakeholders, and upon feedback from there, started iterating with wireframes with real users.
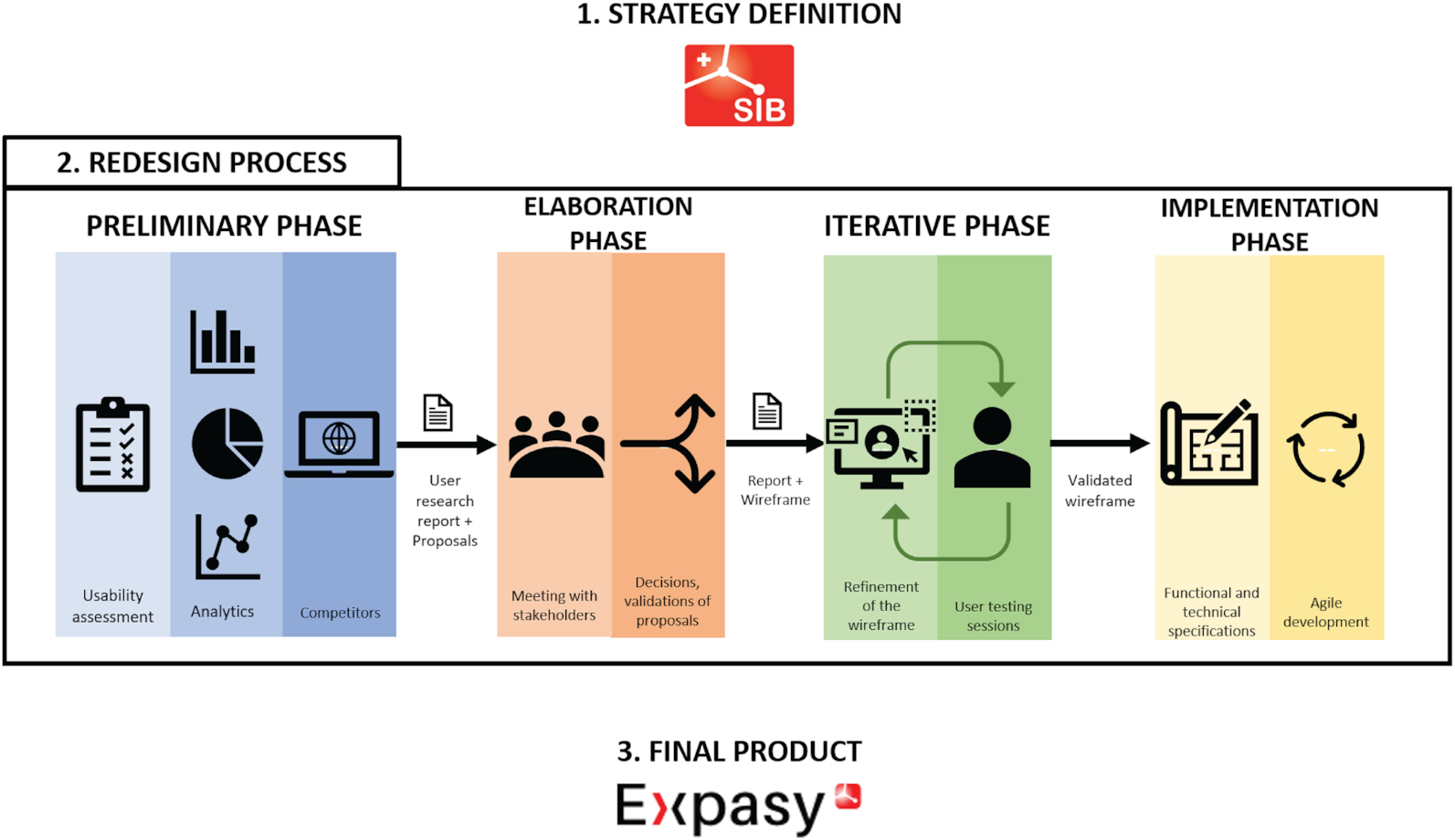
They implemented the new site without breaking old links, making sure that about 5000 URLs which they knew were being at least occasionally used from their analytics were redirected.
The article is a full overview of their process if you’re interested in user-centred design and wondering what it might look like for your products.
Four projects receive research computing support through institute’s seed grants - Penn State Institute for Computational and Data Sciences
Funding for research computing and data support is kind of a mess. Most PIs don’t need multiple FTE-years worth of one specific kind of technical support for their projects, hiring them is hard anyway even if you do have the expertise to evaluate their skill sets, and that’s if you could get the funding. More common is that the need is for a smattering of different skill sets for a few months at a time, but that’s even harder to fund, and to procure. So what typically happens is that some poor grad student gets the technical work dumped on their desk even though it doesn’t fall into their area of expertise.
The only real alternative I see is an agency model, where a PI (especially at the start of a project) can get a short-term team of expertise for consulting and starting a project, and engage with them as the project progresses as needed.
Penn State is doing this with a seed grant program for working with experts at ICDS. Crucially, it’s not just for software development:
Faculty members can apply for support hours from one or more RISE team members for assistance with databases, visualization, code optimization, application development, science gateways, cloud computing, cyberinfrastructure development or other skillsets needed for research in computational and data sciences.
Ideally (I’ll write about this more) the same grant could also involve computing/data hardware access, and would be transferrable between multiple such “agencies” rather than just in-house. But for the majority of capacity needs for research computing and data support, this is the most viable path as far as I can see.
Singularity Registry (HPC) - Vanessa S.
Making a second appearance in two consecutive weeks, this time Vanessa has put together a Singularity repository client that works with lmod to provide singularity instances as module files for HPC systems. The singularity images that are available can be seen here; they include a number of hard-to-build bioinformatics tools, and images that support GPUs.
A sysadmin can make sure that the module system calls
module use /opt/lmod/shpc
and then, e.g.,
module load tensorflow/tensorflow/2.2.2
would load the tensorflow singularity module, and running “tensorflow-tensorflow-shell” would transparently run the singularity image as if it were a local executable file.
Alternatively and maybe more excitingly, a user can setup shpc and have access to those images.
NVIDIA Enters the ARMs Race with Homegrown “Grace” CPUs - Timothy Prickett Morgan, Next Platform
Optimizing Data Movement in GPU Applications with the NVIDIA Magnum IO Developer Environment - NVIDIA developer blog
CUDA Python - Developer Preview - NVIDIA developer blog
The biggest research computing news this week came from a number of announcements made at GTC ’21.
The splashiest news, and one that got a lot of people talking, was NVIDIA’s announcement of their upcoming ARM server CPU, Grace. It is aimed squarely at the AI/HPC market, and will be part of a more integrated fabric with memory and GPUs, with wild proposed numbers for memory-to-CPU and memory-to-GPU bandwidth (that maybe don’t seem so wild after Apple’s M1 breakout). The Grace CPUs will be available in 2023, and will be featured in the Swiss National Supercomputing Centre’s next big system as well as a system at Los Alamos National Labs.
Morgan puts the Grace CPU in useful perspective, connecting it back to NVIDIA’s “Project Denver” started a decade ago, and suggests some likely architectural considerations.
While the CPU news is exciting - and with Graviton, M1, and now Grace it’s hard to view ARM as an upstart for research computing anymore - what strikes me as more meaningful is the increasingly integrated hardware and software stack NVIDIA is proposing. As an example, the GRACE CPU, it is said, will work seamlessly with NVIDIA’s HPC compiler and libraries.
The integration continues with the announcement of the Magnum IO developer environment, which takes existing high-speed communication libraries (NCCL for between-GPU communications, NVSHMEM for shared memory, UCX as a backplane for between-node communications, GDS for GPU-to-storage data transfer, and the cuFile APIs) ties them into common profiling tools, and suggests that they will become increasingly tightly integrated (taking work already done with NVLink and of course Mellanox).
Finally, NVIDIA clearly prefers Python for its non-compiled glue language connecting components; there’s now a preview of a CUDA Python (described more in this NVIDIA blog post) which includes a lot existing packages and adds a common, official, Python API to CUDA functionality which will (eventually) improve interoperability between a number of pieces of the CUDA python ecosystem.
It’s an ambitious programme of effort, and it will be really intriguing to see how successful they are over the next couple of years. Those who can afford it can get a glimpse at this future more integrated stack by applying for access to an NVIDIA ARM Developer Kit which honestly seems like it would be a lot of fun to play with.
Docker without Docker - Thomas Ptacek, Fly.io
Fly.io, which showed up in the Random section of #62, has an increasingly powerful compute-at-the-edge framework - you can give Fly.io docker containers and it will run them out in their CDN, close to your users (or data collection sensors, say).
But they don’t run the services as Docker containers - they run inside lightweight Firecracker VMs (e.g., #59). In this post, Ptacek shows how Fly.io allows users to push a docker image to a secure docker repository, and the steps that are gone through to unpack the docker image (showing how the docker repository API and docker layered file stems work), how those are are bundled up into a loopback filesystem for the Firecracker VM, and how that’s started up. Using Docker as a format for the image lets them make use of Docker’s nice and widely-used tooling for both the users to create them image and for them to interface to (e.g. they run a containerd instance to cache docker images), even if they don’t actually execute the images that way.
The article links to a number of other Fly.io blogposts that might be of interest, such as that for their SSH infrastructure using wireguard.
2021 US-RSE Virtual Workshop - Abstracts due, May 3; workshop 24 and 27 May
Calls are out for 15 minute talks or breakout discussions on topics such as:
ELIXIR Webinar: Towards professionalising data stewardship - 18 May, 15:00 CEST, Free
There has been an effort to professionalize research software development careers; in my view, this effort has mistakely siloed software development from other areas of research computing and data. Areas like research data management, curation, stewardship, and governance also need such recognition and professionalization of career paths. The private sector, or even academic health research is well ahead of us here; the job board routinely has a dozen or so managerial jobs for such jobs in the private sector, particularly in regulated industries like health and finance.
In this workshop, authors of a recent Netherlands report on data stewardship competences, training and education will discuss their reports and steps needed in the Netherlands and abroad.
EDUCAUSE Cybersecurity and Privacy Professionals Conference - 8-10 June, Online - early registration $247 members, $495 non-members
Tracks for the conference include:
Nice post walking through atomics, fences, and memory ordering.
A post extolling VSCode’s new-ish DevContainers for not only deploying but writing code in a container.
JupyterLab 3.0 is out.
A collection of useful GitHub Actions snippets.
A deep dive into CORS, how it works, and best practices.
Meet taskell, a small command-line and terminal based kanban board that lets you import trello boards.
Cloudflare pages is now generally available. I just migrated a static website with a GitHub-to-Travis-to-S3-to-Cloudfront-with-AWS-Certificates deploy cycle to GitHub-with-Cloudflare-Pages and so far everything is way easier. Worth checking out, especially if you already have a GitHub pages site that you’d just like to make faster.
Reminder that PHP is still a thing and it’s maybe better than you remember.