jonathan@researchcomputingteams.org
Hi, everyone!
If you paid any attention to tech management twitter at all in the past week, you heard about how Basecamp started the week by announcing - in a public blogpost! - a new internal policy about how all committees in the company including the new DEI committee was disbanded, and how politics was now forbidden from discussion inside Basecamp or on official accounts, and how it ended the week with 30% of their 50-some-odd company leaving.
I swore I wouldn’t get drawn into that morass for the newsletter, because “managers behaving badly” isn’t the beat I want to be on - it’s depressing, plentiful, and frankly there’s precious little new to be learned from any given episode. There’s a million ways that managers can do things poorly, with many fewer to do things right, and helping managers do things right is where I want this newsletter to be.
But the actual underlying story of what was behind the Basecamp fiasco ended up being being so mundane, so petty, and such an easy trap to fall into I kind of feel like it’s worth addressing.
Back in the day, started by a Basecamp employee who’s since departed, a list started circulating of “funny names” of customers. It kept cropping up and being updated. After the events of the past year, and with the forming of a DEI committee, complaints about how deeply not ok that was started to surface, and calls came for the founders to address it in some way. The founders didn’t want to do anything, someone who hadn’t always behaved completely properly in regards to discussions around those names continued to advocate for something to be done, and the founders responded by pointing out past misdeeds, banning further discussion, and the blog post announcing that any political discussion was verboten, all decisions are made by them, and shutting down committees.
As a manager, our main job is to listen, to make some decisions and enable many others to be made, and to constantly be alive to the possibility that we might be grievously wrong about something. I like to imagine that, working in science, we’re more attuned than the most to the possibility that we’re incorrect. But it gets harder to stay so attuned the longer that people are deferential to you; it takes active practice.
The Basecamp founders could have avoided a self-inflicted minor catastrophe (how would you deal with 1/3 of your team being gone tomorrow?) by just listening to their team, taking the loss even if they didn’t think personally it was that big a deal, and moving on. But they doubled down, and now thousands of articles, including ones in obscure research computing newsletters, are being written about them giving a postmortem and an incident report.
It’s not easy to back down as a manager, and it’s easy to get personally invested in individual decisions. But it’s not about us; it’s not even necessarily about the team; it’s about the impact we want our team to have. We have to be willing to walk back poor decisions when they get in the way of achieving the things we want our team to achieve.
Anyway, with that, it’s on to the roundup:
A thorough team guide to RFCs - Juan Pablo Buriticá
We’ve written before about design documents architectural decision logs (e.g. #33) and using collaboration around documents as a form of asynchronous meeting (e.g. #49). Usually the thinking is that someone in charge has initiated the document. Buriticá writes about team member-initiated requests for comments as a proposal for a change or the creation of something new, which can then go through a comments phase like a PR, and an approval phase where whatever decision making process is appropriate plays out and people get to work implementing the proposal. In this respect it’s like a Python PEP or a W3C RFC.
This approach is very consistent with a model of delegating to and developing your team members - turning every team member into a technical leader by having them propose, revise, and gain support for technical directions in their area of expertise.
How to Run Effective 1:1s - Luca Rossi
The big guide to One on Ones (1:1s) for Managers - Matt Nunogawa
It’s always good to refresh the basics, especially when hearing from someone new.
Rossi emphasizes, correctly in my opinion, the relationship-maintenance aspect of one-on-ones - maintaining the lines of communication is at least as important as what is communicated in any particular one-on-one. He also has this nice image about how having a scheduled opportunity to touch base frequently makes it much easier to make nudges and keep things on course than having less-frequent one-on-ones (or worse, not having them at all):
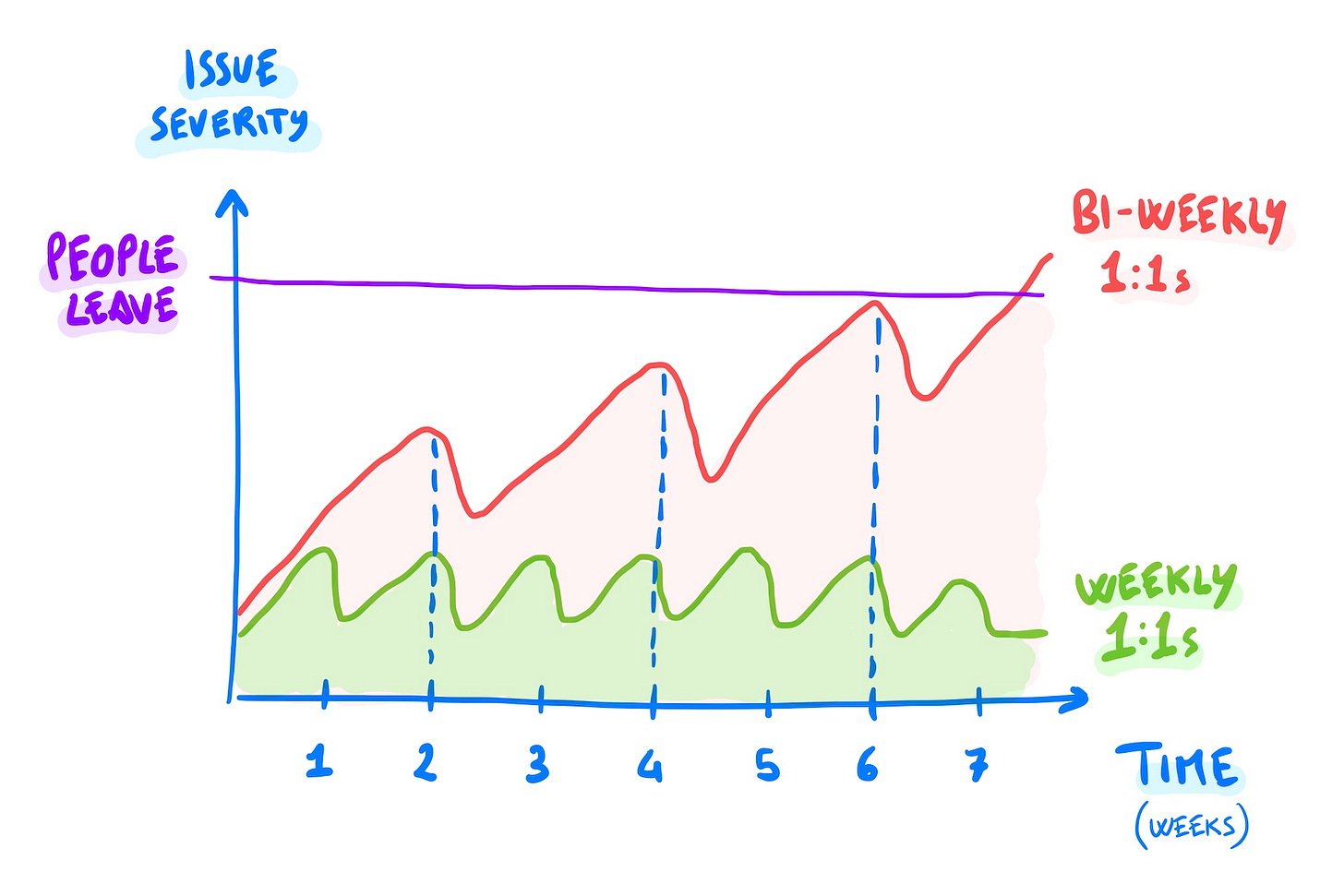
Both are good short reads, especially if you’re not already doing routine one-on-ones.
Inclusion in a Distributed World - Christoph Nakazawa
Most of our teams are going to be moving to some kind of hybrid model of distributed and office work, and this mixed approach is notoriously difficult to get right. So it’s important to start figuring out now how to make the transition and what the future will look like.
Nakazawa talks us through some of the issues - principally, if there is an “in office” and “remote” split in the team, it is really really easy for the “remote” team members to become an afterthought. On top of the obvious stuff - when calling into meetings, everyone has to call in from their own device, so everyone experiences the meeting as a virtual meeting - there have to continue to be structures in place to build a cross team culture.
Nakazawa talks about maintaining virtual team social events, and including team culture as part of retrospectives; but also of doing planning together as a team, and maintaining asynchronous, document based collaboration and decision making (like RFCs above).
We’ve largely learned how to do these things in the coming year; in the rush to get “back to normal” we don’t want to loose these trickier but more flexible and powerful collaboration skills we’ve learned. If we keep using them and keep those muscles in shape, we’ll be able to hire remotely and still maintain the strengths of our skills.
The Workshop Workshop - Christina Maimone, Northwestern Research Computing Services
A lot of research computing teams provide training to their research communities, and a question that comes up from time to time is how to better scale that effort up. Often that conversation turns to creating a mini-MOOC type course, with online self-paced materials and automated grading, possibly with TA office hours. That is a great and sadly underused approach.
Maimone writes about another, at Northwestern:
We want to see more members of the Northwestern community confidently and effectively teaching the data science and programming skills they know to others. So we’ve created what we’ve been calling The Workshop Workshop, AKA Data Science and Programming Workshop Design.
Northwestern RCS is scaling up their training efforts by teaching others in the community how to put together workshops using their well-established approach. This is a really good idea; most groups who do routine trainings have some process to generate them. Teaching that material will both help others do some of the training, and improve their own internal processes (and onboard new hires into it).
Congress Should Fund $500M in Near-Term Quantum Computing Applications, Establish a National Quantum Research Cloud, New Report Argues - Centre for Data Innovation Press Release
There continues to be increasing calls for funding hardware and research projects into quantum computing. Besides the advocacy itself, this report (PDF) has a short overview of some of the currently most promising use-cases for the sort of optimization problems quantum computing might support.
A field guide to cultivating computational biology - Carpenter et al.
As comes up from time to time, research computing isn’t the only area trying to establish a stable and respected career and funding path for computing-intensive work. Carpenter et al. address how to support computational biologists. Their recommendations look similar to 20 years of recommendations for supporting research computing and data teams:
After decades of this I’m not really convinced that these earnest entreaties are going to do much good; the only real progress we’ve made on these sorts of issues have come from elsewhere (e.g. COVID has supercharged interest in sharing data more widely).
U.S. students respond well to emergency remote learning - Tony Bates
It’s worth celebrating our and the research/higher ed communities successes over a really challenging year. Bates summarises a study of 1469 US postsecondary students (with similar numbers of faculty/administrators) about how the emergency shift to remote learning went. Obviously everyone was marking on a curve here, thinking in terms of “given everything”, but even still, in Fall 2020 when everything was new:
73% of students gave their courses A (43%) or B grades (30%); only 11% gave a D or F
This is pretty remarkable, and should be celebrated. (This also echos the success we saw in #64 of Bristol’s abrupt move to virtual trainings) The downside was that it was all really hard on everyone:
All three groups (students, faculty and administrators) reported that stress was the most pressing challenge, followed by maintaining motivation and then having coursework to do.
We know that the stress and challenges weren’t evenly or equitably distributed distributed, and that’s both a problem and a symptom. But maybe we can learn through what happened and build on what has been done.
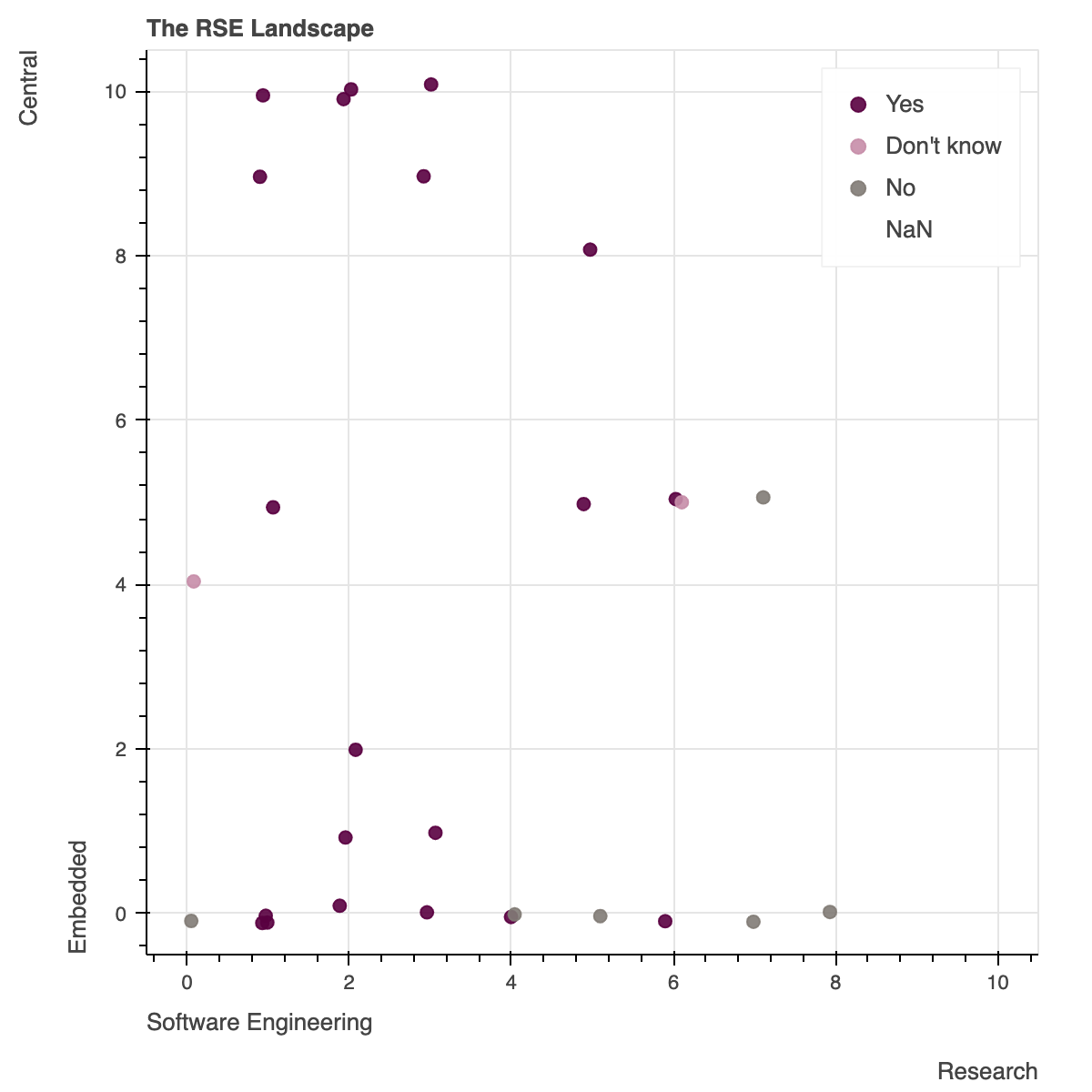
The RSE Landscape - Teri Forey, Society of Research Software Engineering
This is a survey of a relatively modest number (36) participants of a Software Sustainability Institute workshop, 23 of whom considered themselves to be research software engineers, regardless of their title. Respondents typically were more on the software development side of things than research, and that was typically well aligned with their career goals. A disturbing number, particularly with academic postings, were on term-limited contracts, which is a problem for those trying to build a stable career.
Another interesting question asked whether they were embedded in particular teams or part of a centralized team; there seemed to be a roughly even split.
This is a small survey, but data on how real-world RSE teams and jobs are structured are hard to come by, so every datapoint is welcome.
A Better Model for Stacked (GitHub) Pull Requests - Timothy Andrew
Large PRs are notoriously hard (and slow) to review, and tricky to merge if during the long review process a number of things has changed in the meantime. In this post Andrew argues for an incremental approach, with a number of smaller PRs “stacked” upon each other.
The tricky part here is if the PRs undergo changes during the review process which cause commits. In that case, to keep commit history clean, Andrew suggests cherry-picking the commits one PR at a time and committing them to the main branch, and he has some scripting tools to help with this. The alternative is to introduce a large number of conflict-fixing merge commits in commits down the stacked chain.
The article includes nice sidebars on how (e.g.) rebase commit deduplication, and clarifying git animations.
An Ansible-driven Slurm “Appliance” for an HPC Environment - Steve Brasier and Will Szumski, StackHPC
The StackHPC team has put together open-source ansible playbooks to deploy a CentOS 8-based slurm cluster with an OpenHPC stack, NFS-mounted shared filesystems, graphana, prometheus, and elasticsearch for monitoring and logging, and a compute-image deployment system based on Packer. Being ansible based it works in a variety of contexts, from bare-metal on-prem deployment to atop VMs in clouds:
In addition, its modular design means that the environment can be customised based on site-specific requirements. The initial list of features above is just a starting point and there are plans to add support for identity/access management, high-performance filesystems, and Spack-based software toolchains. We fully intend for this to be a community effort and that users will propose and integrate new features based on their local needs. We think this combination of useability, flexibility and extendability is genuinely novel and quite different from existing “HPC-in-a-box” type offerings.
It also seems like a pretty easy way to poke around with the OpenHPC stack.
I’d love to see more teams and centres release their hard-won operations experience in readily useable forms like ansible playbooks.
We have sections here for software development and systems, but nothing for research data management and analysis; every couple of weeks this shows up as an article shoehorned into an odd match for a section. Let’s fix that by having a recurring section for topics of data management, data science and data engineering.
You might as well timestamp it - by Jerod Santo It’s not uncommon in a data model or database to have boolean flags to say if a piece of data has been curated, or the calculation has been done, etc. Santo urges to replace those fields with something more meaningful - a timestamp.
Even in the rare case that you never need that timestamp… what have you lost? Its cost is negligible, both in data storage and coding overhead. Your code merely needs to consider a NULL timestamp as false and any non-NULL timestamp as true and there’s your boolean use-case.
Data Cascades: Why we need feedback channels throughout the machine learning lifecycle - Ben Lorica, Gradent Flow
The importance of data quality certainly isn’t news to those in research, but some of the issues flagged here by Lorica (or in the Google Research paper (PDF) it refers are extremely relevant.In fact, the Google paper (titled “Everyone wants to do the model work, not the data work”) suggests one big issue - misaligned incentives.
Across research, there are key major data resources which are fundamental to many researchers, but they have to routinely fight for funding to stay up and running, and to continue their curation work. Other challenges identified are:
Ultimately both in science and in industrial applications of data science, there needs to be tighter feedback between the data consumers and the data stewards to make sure data (including metadata) quality is kept high and up to date, but there are structural issues that have to be overcome for that to happen.
ARM Puts some Muscle Into Future Neoverse Server CPU Designs - Timothy Prickett Morgan, The Next platform
Arm Launches New Neoverse N2 and V1 Server CPUs: 1.4x-1.5x IPC, SVE, and ARMv9 - Wikichip Fuse
Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility - Andrei Frumusanu
Two years ago the announcement of new ARM chips would have been pretty niche news in research computing. Now with the price/performance benefits of AWS Graviton being clear now even some traditional research computing workloads, and the Apple M1’s splashy entrance, there’s a lot more interest. This announcement includes new cores (the N2 and V1) a design for a new inter-core mesh supporting more cores per socket, improved off-socket interconnects,
The N2 cores are the evolution of the N1 cores in the Graviton, with DDR4 and PCIe-4 support, and a new interconnect to better support NUMA or accelerator workloads. It’s still quite targeted at scale-out (e.g. cloud) workloads.
The V1, however, is targeted squarely at AI (and thus to some extent HPC) workloads. It’s aimed to have performance per core at something more like typical x86 cores, various tuning available to keep power under a given envelope. It also scalable vector extension allowing access to (currently) 256b wide vectors (but, as we talked about in #57 with RISC-V, the same instructions would work work with wider vectors in upcoming chips). Because AI is a big market, it supports bfloat16 and Int8s as well.
OpenMP Hackathon @ENCCS/Intel - 8-9 June
Apply for a spot in an OpenMP hackathon; bring your own C/C++/Fortran project to work on.
To apply for participation in the hackathon you will need a well-defined project with clearly stated goals, and we recommend you to join a team with at least 2 people. Invited teams will be paired up with experts from both Intel and ENCCS/SNIC who will provide hands-on mentoring and pair-programming sessions. Note that hackathon participants should also attend the training workshop on June 1-2.
vCHEP2021: 25th International Conference on Computing in High-Energy and Nuclear Physics - 17th-21st May, Free
HEP has built a lot of really important research computing tools in the past, and is increasingly an adopter of new and emerging technologies - worth keeping an eye on this conference as the program is updated.
ACM SIGSIM Conference on Principles of Advanced Discrete Simulation (PADS) - May 31-June 2, Online, $250 non-members
A broad conference on methods for and applications of discrete-event and agent-based simulations.
Over the years PADS has broadened its scope beyond its origins in parallel and distributed simulation and now encompasses virtually all research that lies at the intersection of the computer science and the modeling and simulation fields.
It’s easy to forget the industrial-scale scanning of sites like GitHub for credentials. Here’s an alarming story of someone who leaked their Google cloud credentials onto just a random GitHub repository for five minutes and found nearly 200 instances being used to mine Monero shortly afterwards.
More proof cryptocurrencies are ruining everything - free-tiers of CI services are limiting/worsening their offerings at least in part because of rampant abuse by crypto miners.
An article about lmgrep, a simple command line tool for parsing plain text files, and using Lucene’s text analysis machinery to tokenize and stem the words, perform simple editing, and otherwise prepare the results for more sophisticated analysis.
A rare article in favour (extensively so) of YAML, calling out in particular the additional functionality it has that JSON does not.
A clear explanation of the difference between shell builtins and programs, and the consequences for the use of environment variables.
Compiling C++ programs with make -j100 using AWS lambdas and llama.