jonathan@researchcomputingteams.org
Hi, all!
Here our team is continuing to make post-pandemic plans for how work will work.
Others are further ahead. This week Apple confirmed their very office-centric plans, and Asana’s similar plans came up again. Apple, which is very much a product company relying on close integration of the work of software, hardware, industrial design, and even materials science teams, very dramatically doubled down on its office-based approach - with a surprisingly flexible (for Apple) approach of allowing up to two days a week remote for some teams, and an unsurprisingly (for Apple) inflexible approach of firing people who leaked internal Apple discussions to the world. Asana is requiring even more on-site time, 4 days a week (the 5th day being their long-held tradition of no-meetings Wednesdays), but with increased flexibility in working hours and conditions.
I definitely think that switching to remote-first is a huge potential opportunity for many research computing teams, and one we all should consider. But it’s not the only model available, and looking back I worry a bit that I may not have given the other obvious model its due, especially for those at Universities.
For the largely hospital-based, multi-institutional, software development team that I work on, remote-first will work quite well; but other teams have other constraints, and other benefits from being on-site. Remote-first will make hiring some candidates easier for my team, but for (say) University teams, being on campus can be a real attraction for others.
A lovely campus with quads and cafés, feeling like part of the hustle and bustle of research and teaching, being able to duck out for an hour in the afternoon to sit in on a colloquium or lecture, visiting the cutting-edge labs of researchers you are supporting — these are all major selling points to the right candidates. They’re also features we’ve typically taken for granted, and since there’s absolutely no way teams in academia can compete on compensation these days, they’re features we should be collectively playing up.
Whatever model we end up choosing (or having chosen for us by institutional requirements), there’s nothing wrong with embracing and leaning into it. If I were back in a University and we were staying on-site, I’d give serious thought to making sure a list of relevant seminars (and auditable courses) on campus was being maintained and available to the team, arranging lab tours, pushing for on-campus meetings wherever possible, etc., and including them in job ads along with some things I previously took for granted (like a couple weeks off over the holidays). The right new candidates will find this appealing, and they are perks that can’t be readily offered by tech firms. We need to play up all of our unfair advantages, which are many.
Either remote-first or office-first models are going to be easier to communicate and manage than hybrid approaches - which admittedly cover a lot of ground. I’m really interested to see what approaches pop up, and how we can use them to our advantage in research computing.
For now, on to the roundup:
There’s a couple of items this week which go back and forth between managing your own career and helping your team members, so let’s merge the sections this time:
Filtering your language as an engineering leader - Rob Begbie, LeadDev
Borrowing Lines from Great Leaders Around You - Lara Hogan, LeadDev
Everyone who’s managed or been a team lead for long enough has had the experience of thinking aloud or asking an idle question and then having a team member waste hours following up on what they thought was now a Suddenly Important Thing.
As a manager we need to stay involved in the work enough to understand what issues are likely to come up while not micromanaging the work - letting the team members make the decisions they’re best placed to make. That means we need to be asking questions, probing, and checking our understanding, while providing our team members clear context that that’s what we’re doing and inviting corrections rather than them thinking these are directives.
Begbie provides some linguistic context-setters - he, following author Robin Sloan, refers to these as “linguistic instagram filters” - that he uses (and when he uses them). My favourites in this context are:
Two things I’d like to add. First - that last approach in particular, where you listen to a problem or proposed solution and then try to explain it in your own words to check that you understand, is an incredibly useful technique in almost any setting. Communication is hard, and pausing to verify that accurate communication has in fact taken place is so so so helpful. My own version of that last phrase is: “[listens carefully, asking clarifying questions here and there]… Ok, so let me see if I understand this…. [my re-explanation]. Is that close? What did I get wrong?”
Second - as a new manager, it will feel weird to have set phrases that you say over and over again. Don’t worry about it. It is good and useful to keep using the same phrases. One of the things a decent manager brings to a team is a certain amount of stability and even predictability in their actions. If you want to experiment with a different phrase to see if you get even better results, outstanding, please do, but don’t change up things you say just because you feel funny repeating yourself. Communication is hard. A conversation starter that has been used often enough for everyone on the team know exactly what context it sets is a valuable thing.
In the second article, Hogan suggests going further and actively seeking out useful approaches and phrases in meetings and conversations you’re in, then poaching them and making them your own. She particularly suggests keeping an eye on how people:
As you start watching experienced (or just talented) leaders and team members participating in meetings for these sorts of approaches, you’ll start collecting lots of potentially useful tools for the tool box. You might have to re-cast them in your own voice, and they may take a few times to work in your team, but learning from others is how we work in science and in leadership.
The Hotel Giraffe - Michael Lopp, Rands in Repose
There’s a lot in here about stress, how it builds up, and how it’s hard to see sometimes from the inside.
Lopp has four questions he asked his team members during a previous job:
On a scale of 1 to 10 (1 == low, 10 == high): How stressed are you right NOW? What is your IDEAL stress level? Ideal meaning the stress is useful and not debilitating. What is your MAX stress level? What behaviours do you see in yourself when you close or at MAX?
Most of us in this line of work like to be a bit stressed, if the stress is of the right kind - learning challenging new material, developing new skills, reaching to make stretch goals. But when stress builds up, it gets unproductive (sometimes this distinction is referred to as eustress vs distress). Lott walks through his failure modes when he’s near max stress:
Lossiness: I become unreliable. I miss on commitments and I’m not aware I’m doing so until reminded after the miss which leads to
Irritability: Small annoyances have a disproportionate effect on my mood. I have strong negative reactions to small developments that I normally easily shrug off. Then I start to become
Increasingly Pointlessly Tactical: Stuff is dropped, I’m grumpy, so I start to make lists. Lots of them. […]
Rage: The final straw. When we’re not all following my irrational unspoken script, I get rage because of my totally unrealistic expectation that everything must proceed exactly to plan.[…]
I think mine are pretty similar; certainly lossiness and irritability are early warning signs.
Much of the article is a particular example of how he only belatedly discovered he was very stressed out because he was missing on commitments to himself (food, exercise, sleep). The key is to pay attention to early warning signs - in yourself as well as your team members! - and then course correct, rather than letting things go too far.
Leadership in Data Science: Lessons Learned From Time Invested in Helping to Build the Field - Patrick J. Wolfe, Harvard Data Science Review
Data Science and Computing: The View From a Sister Campus - Hal S. Stern, Debra J. Richardson, and Marios Papaefthymiou, Harvard Data Science Review
These two short commentaries on a longer article, how data science and computing is being organized at UC Berkeley by Jennifer Chayes (Associate Provost of the Division of Computing, Data Science, and Society). Both Wolfe and Purdue and Stern, Richardson, and Papaefthymiou at UC Irvine, give some advice based on their experiences at those institutions. The approaches outlined in both papers are important not just in data science but across research computing and data and really any research support role.
Wolfe emphasizes matters of approach, that to be a trusted partner in inherently interdisciplinary work and thus to support research, it is important to:
In the second, Stern et al. at UC Irvine emphasizes structural and institutional structures, including the building of educational programs, the creation of centres for applying discipline-specific expertise to data in various domain, and cross-institutional collaborations these centres can enable within those disciplines. This work also emphasizes that lack of staff is too often the limiting factor:
A challenge that we have found at UC Irvine is that a limiting factor for advancing data science collaborations on our campus—and we imagine this is true at many universities—is that there are not enough people with the data skills and computing expertise to meet the needs of campus research teams.
Hardware Memory Models - Russ Cox
With ARM processors becoming more common in research computing - likely more popular than POWER processors ever were - it’s important that the developers of multithreaded software understand the much looser memory consistency semantics of ARM and POWER over x86.
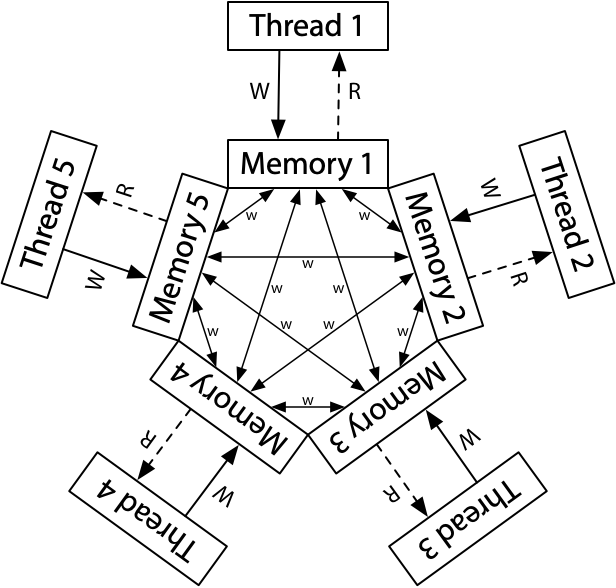
Cox walks us through how the Total Store Order of x86 cores work, and then the more relaxed ARM/POWER memory model which has much weaker consistency guarantees. Even for developers who are relying on libraries and tooling like OpenMP runtimes to handle memory barriers for them - which hopefully is most of us! - it’s useful to know the underlying mechanisms and what can go wrong.
I’m really excited by the potentials of AI-based code completion like GitHub Copilot - research computing has too much boilerplate and drudge work compared to web development, where a lot of work has gone into frameworks to help. But others are much less enthusiastic, and there are real questions about whether all the code that went into training the Microsoft/OpenAI model was licensed to allow this.
Relatedly, this week I learned about Wingman for Haskell, which uses a logic/solver based approach (I think) to try to write out code to meet the often complex type definitions of Haskell functions.
Querying Parquet with Precision using DuckDB - Hannes Mühleisen and Mark Raasveldt, DuckDB Blog
As you know we’re big fans of embedded databases (SQLite and the ilk) around here. DuckDB is a columnar embedded database, aimed at supporting analytical queries more than row-by-row transactions. In research computing, many of our use cases are more analytical than transactional, and so these sorts of databases are interesting; I’ve played with DuckDB myself a few times.
DuckDB has its own file format for databases, which it turns out maxes out at about 4B rows (go ahead, ask me how I know), but it can also directly query from Parquet files, a standard file format for columnar data, where there is no such limit. Unlike its own internal format it can’t persist an index for such files, but parquet was meant to be streamed through quickly (and supports sharding) so it can be very fast (especially on fast storage). In this blogpost, Mühleisen and Raasveldt demonstrate how much faster DuckDB’s python client is than pandas for querying such files, but like sqlite it also has a pretty standard CLI for querying.
Introducing PathQuery, Google’s Graph Query Language - Jesse Weaver, Eric Paniagua, Tushar Agarwal, Nicholas Guy, and Alexandre Mattos, arXiv:2106.0979
Introducing PathQuery, Google’s Graph Query Language - John Zabroski
In #23, we talked about SQL/PGQ and then GQL, proposed incremental additions to SQL to support first property graphs (PGQ) and then a graph-specific query language (GQL) to query those property graphs.
Google has written up a paper on PathQuery (PQ) a graph query language written from scratch to support Google’s Knowledge Graph. As Zabroski points out, an interesting difference between PQ and any of the SQK variants is that it’s a proper programming language, with modules and a compilation step, and a relational algebra to make a number of well-known optimizations possible. Apparently Google has 40,000 path query modules already written that can be used internally. I wonder how long it will be before we see an open source implementation of this?
It’s a networking-palooza in the systems section this week:
How a Docker footgun led to a vandal deleting NewsBlur’s MongoDB database - Samuel Clay, NewsBlur Blog
Always love a good postmortem. Here NewsBlur (think Google Reader - an RSS eader service with a social component) had their MongoDB database of articles, etc. deleted because of how docker, iptables and ufw interact. That ended up exposing the MongoDB container to the world - and unfortunately, the mongo database didn’t have authentication set up, so once a vandal was through the firewall it was game over.
There’s a good story here about backups and logging, and not depending on a single line of defence. I think Clay is a little unfair to docker here though:
When I containerized MongoDB, Docker helpfully inserted an allow rule into iptables, opening up MongoDB to the world.
The issue here is upstream of Docker (and applies to podman if not running rootless, for instance). Traffic to containers are forwarded and so follow the FORWARD chain of the filter table in iptables, not INPUT, and ufw only lets you easily manage the INPUT chain. My understanding is that docker-compose, which by default sets up internal shared networks, doesn’t have this problem. And obviously this only applies to on-node firewalls, external ufw/iptables firewalls “north” of the system would be completely unaffected by this.
There are ways to address this issue on-node like running docker with —iptables=false or being very careful about the order in which you apply rules, but Clay’s description of this as a footgun is perfectly fair - it’s certainly unexpected interaction and not nearly well-known enough.
Accelerating Scientific Applications in HPC Clusters with NVIDIA DPUs Using the MVAPICH2-DPU MPI Library - Gilad Shainer, Dhabaleswar K Panda and Nick Sarkauskas
Looking Behind the Curtain of EVPN Traffic Flows - Rama Darbha, NVidia Developer Blog
Using VXLAN Routing with EVPN Through Asymmetric or Symmetric Models - Rama Darbha, NVidia Developer Blog
Even though NVIDIA’s purchase of Mellanox has been planned for over two years and was completed over a year ago, it’s still weird to me to be reading networking articles that have nothing to do with GPUs on the NVIDIA blog.
The first addresses Data Processing Units or “DPUs” - the new marketing term for accelerated network cards and/or storage interfaces. These devices are now typically somewhat more programmable and may connect network, memory, and storage. Intel has decided (not entirely unfairly) that they’ve been doing DPUs for ages - so much so that they’re already bored with it and will call their new stuff IPUs, Infrastructure Processing Units. Either way, while the new marketing term is the biggest step-change advance, the last year or two has genuinely given us real increases in the capabilities of these accelerated and smarter network processing devices.
Shainer et al. give an overview of the capabilities of their new BlueField SmartNIC/DPU/IPU/whatever — which at 8 ARM cores with 16GB of shared onboard memory is a pretty serious compute platform in its own right — and walk us through their partner’s distribution of MVAPICH2, MVAPICH2-DPU, which looks like it will be a commercial licensed product. By pushing nonblocking collectives like Ialltoall to the DPUs, it can accelerate the OSU Ialltoall benchmark by 17-23% on 32 nodes, and P3DFFT (which relies on nonblocking collectives) by 12-21% on 32 nodes.
The second and third articles have Dharba give us more general and non-NVIDIA specific deep dives (with demos you can run on your own box) into ethernet VPN (EVPN), and how it works (in the first article) and how it interacts with VXLAN (in the second article) for routing. I’ll admit to you, dear colleague, that they go deeper into networking fundamentals than I can follow, but the articles and collected resource (including the demos) seem like a good place to start if I wanted to learn more about these areas. (Corrections welcome from those of you who work with this stuff regularly!)
DevOps; a decade of confusion and frustration - Jan Harasym
DevOps started as a pretty simple idea - breaking down (or at least making more porous) the wall between two groups, developers and operations staff, with with diametrically opposed incentives. There is tooling now that helps (but isn’t essential), and skillsets that help (although as Harasym points out, sysadmins have always had coding skills, and lots of developers have long had some sysadmin skills), but the key is just alignment.
Unfortunately, devops has become a widely misused term. I’m guilty of some of the sins Harasym outlines myself, having (recently!) been on the lookout for a potential new “DevOps hire”. But that’s not a phrase that means anything. DevOps is an organizational approach, with developers and operators working together; it’s meaningless when applied to a single person.
Harasym urges us for clarity to continue to distinguish between roles which are principally operations/sysadmins, developers, and things like release/pipeline/workflow managers. If you try to hire someone for “a devops role” or advertise yourself as a “devops engineer” no one will know what you mean, because it’s an empty statement. On the other hand, an “operations/deployment professional on a devops team” actually communicates something.
The (Resilient) HPC Market Writ Large in 100-plus Slides by Hyperion - HPC Wire
HPC Wire gives us an overview of Hyperion’s HPC Market Update briefing during ISC2021, focusing on total spending and breakdown by sectors. Some things that I think matter are:
The cloud component is growing increasingly interesting, with several shots across the bow from cloud vendors on the top-500 list - Azure having 4 systems tied for 26 on the list, NVIDIA A100 + Infiniband HDR in different regions (to make it clear, presumably, that they field these special HPC Infiniband data centres across the US and in the EU), and an AWS cluster in 40 on the list with just Xeons, 25G ethernet, and (presumably) their EFA/SRD low-median-latency networking atop the ethernet we’ve talked about several times before.
ACM Europe Summer School on HPC Computer Architectures for AI and Dedicated Applications - Applications due 15 July, Virtual Summer School 31 Aug - 3 Sept
This year’s summer school hosted by BSC will be fully remote. It’s aimed at early-career CS researchers and engineers, with some spots available for outstanding MSc or undergraduate students.
2021 International Workshop on Performance, Portability & Productivity in HPC - 14 November (as part of SC21), abstracts due 27 Aug, Papers due 3 September
Topics of interest include:
Azure for Researchers part 1: Introduction to Cloud Computing - Ongoing, Microsoft Azure, 5hr45, Free
Azure for Researchers part 2: Cloud Security and Cost Management - Ongoing, Microsoft Azure, 2hr22, Free
Microsoft has just released two Microsoft Learn self-guided courses specifically for researchers - one on the basics of cloud computing in Azure for researchers, and the next one specifically looking at cost management and security.
MNHack21: 3rd Marenostrum hackathon - Team registration due 15 Sept; hackathon is 2-4 November, on-site in Barcelona
The 3rd Mare Nostrum Hackathon, using the MareNostrum4 supercomputer at BSC, is taking team applications, due 15 Sept. Registration is free, and teams will be provided mentors for the hackathon.
Oracle wants you to know that they provide commercial cloud offerings, too, and that they’ve recently expanded their free tier offerings.
Keeps getting easier to use webasm to push complex and relatively performant code into the client’s browser - here’s a 6 step guide going from C functions to webasm called by javascript.
A vim guide for veteran users.
Learn a bit about theorem proving software, and lean in particular, while playing sudoku and justifying your moves.
Javascript now has a much better date/time API, Temporal.
For those of us using Slack (which is a lot of us), they’re rolling out some very useful new features - scheduled messages (FINALLY), and some I’m curious to try - lightweight audio huddles, and (coming soon) easy async video/audio recordings.
Cute overview of how fly.io recommends handling geographically distributed postgres instances by putting modest amounts of logic in the proxy layer for writing.
XSEDE has added some new badges to their training offerings.