jonathan@researchcomputingteams.org
Hi - I hope your week has gone well.
I’ve been prompted by a few things to think about activity versus accomplishing lately.
Falling into a trap of doing stuff, and so feeling busy and industrious, but not actually getting anything meaningful accomplished is certainly a trap that individual contributors can get ensnared in. We’ve all worked with someone (“or been someone”, he said sheepishly) prone to bike shedding or yak-shaving or some other flavour of spinning around in a rabbit hole without making forward progress. (Whenever I have to explain yak-shaving to someone, this is the youtube video I point them to). It can feel like work to the IC, but to an external observer it’s pretty clear they’re stuck - they were tasked with doing the thing and they are very visibly not taking the direct route towards doing the thing.
But wow, with managers and above, the trap is way more subtle - and it’s not nearly as obvious to those around us when it happens.
Our work as managers or technical leaders is inherently only indirectly connected to the things getting done. We keep the team aligned on goals, so that the right things get done. We provide feedback and coaching so our team members can do things more effectively. We delegate so that our team members can individually do bigger things. We engage with stakeholders to find out what thing-doings need prioritization, and then we plan - now we’re getting two or three steps removed from things getting done.
So it’s deceptively, insidiously easy to fall into the trap of doing things that look like those important activities but have become unmoored from actually advancing the work of your team or the development and support of your team members. To have meetings or planning sessions that may have been relevant at one point but now don’t actually advance any goals. To engage with and collect feedback or input from stakeholders because that seems like the right thing to do, but the input doesn’t connect to any next steps - you’re taking measurements that aren’t informing decisions about anything concrete.
On my end, I’m on the periphery of engagement with an organization now that is very visibly being very busy doing stuff but not advancing meaningfully on any front. And seeing that is actually kind of useful, because it’s making me re-evaluate some of the activities I’m doing. One or two of them seemed like a good, well-motivated idea at the time, but in retrospect can be deleted with zero ill effects.
The only way as managers we can really tell is by having extremely clear priorities in mind, ideally in service of some kind of strategy, and being absolutely relentless about purging tasks that don’t advance those priorities. Like everything in management, it’s not complicated - but it takes discipline to keep doing it.
How to Get Your Silent 1-on-1s Back on Track - Emmanuel Goossaert
Whether it’s trust issues, or just overwhelm, one-on-ones can get quiet from time to time. For almost any other kind of meeting, if the meeting is short because there’s not much to say, that’s a win! But the purpose of one-on-ones is maintenance of a line of communication, more so than what is actually communicated in any given week. If that line of communication isn’t functioning, we as managers need to do the maintenance work to get it the communication flowing again.
Goossaert suggests having a library of open-ended questions to prompt conversations:
The lettuce pact: The ultimate hack for giving difficult feedback - Brennan McEachran, Hypercontext
If you’re struggling to figure out how to improve your team’s frank but kind feedback to each other, McEachran has a suggestion. Riffing off a discussion from the Radical Candor team, the suggestion is to make things concrete, with a personally embarrassing but minor situation like someone about to give a talk with spinach between their teeth. They clearly have a right to be told, and there’s clearly better and worse ways to share it with the person, but it’s hard to know how to bring it up. It’s a good way to frame the discussion of giving feedback.
I think McEachran takes this too far and not far enough - a formal agreement 1:1 with each team member, but focussing only on personally embarrassing feedback rather than more generally telling someone that they’re not meeting an expectation - but nonetheless it may be a useful starting point for discussing feedback within your team.
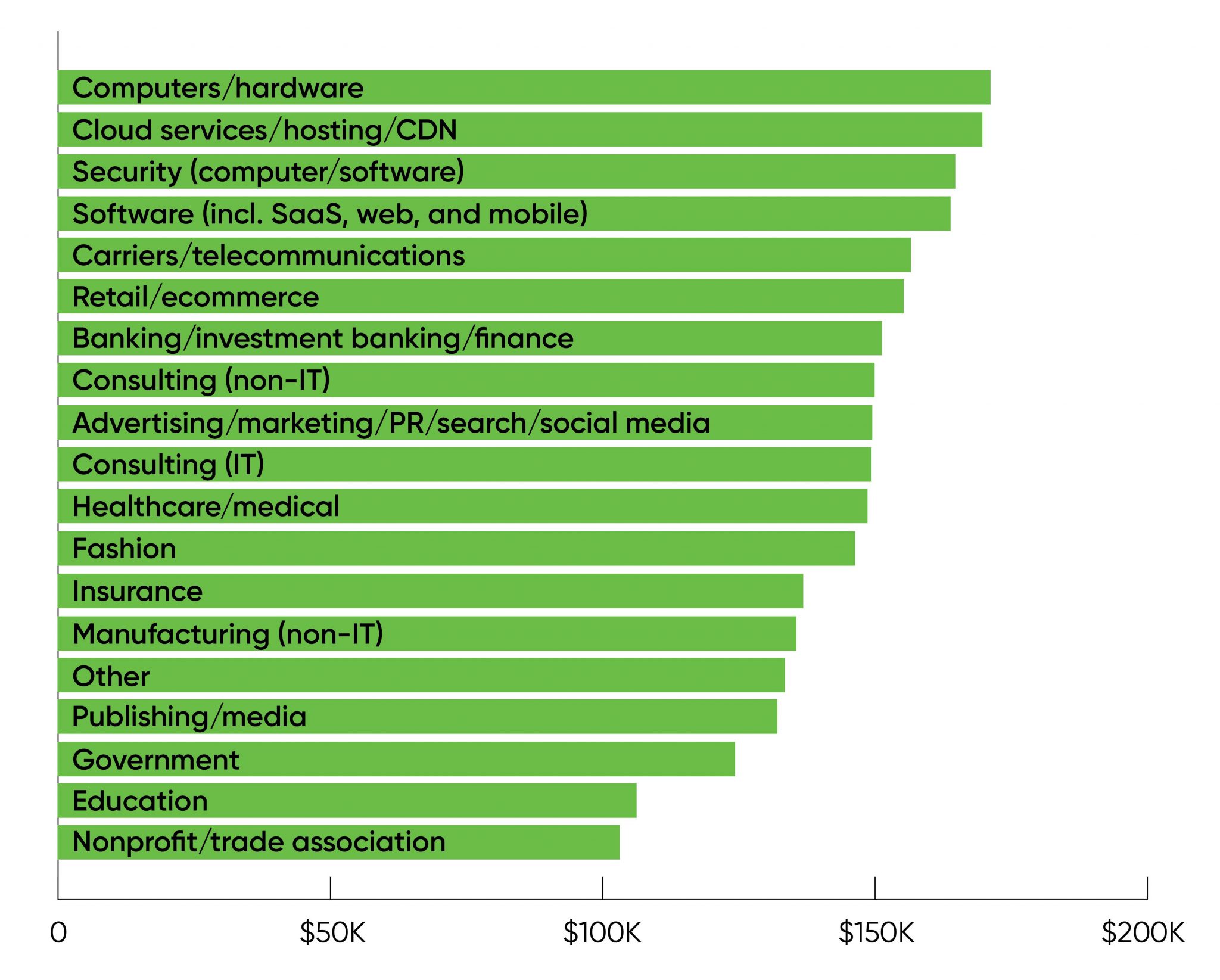
2021 Data/AI Salary Survey - Mike Loukides, O’Reilly
Apropos talking last week about hiring, and higher salaries in industry: a salary survey of 2,778 people in the US subscribing to the O’Reilly Data and AI newsletter found average salaries of $146,000 USD, and that includes the 31% who listed “Excel” as one of their main data tools (with salary $138k). Of course, these early data scientist-track jobs pay significantly less than software developers or infrastructure teams pay, as a quick glance at salary sites like levels.fyi will tell you.
In the survey, people working in the cloud or with ML frameworks (Spark ML, $175k; even scikit-learn $157k) had significantly higher salaries.
Salaries were highest in tech ($160+) and lowest in non-profits and education (roughly tied at ~$100k).
It’s ok - not great, but ok - if our salaries are that much lower, but we need to be clear-eyed about the disparities, and make sure that we’re making the work and the environment of the team worthwhile enough that they’re willing to take a substantial pay cut.
Also noted was a discouraging pay inequity, with women making 70-80% of what men make, and with an appallingly low 14% of respondents identifying as women.
Being the DRI (Directly Responsible Individual) of Your Career - Cate
One of the benefits of being a or working with research trainees is that it drives home that we’re not going to be retiring from our roles (grad student, postdoc) - they’re stepping stones, usually to new institutions, and that we’re responsible for our career development.
Even so, once we get a staff position, it’s easy to forget that. Cate enjoins us to keep it in mind, and be relentlessly in charge of our own professional development and career next steps:
My employer buys my time, they rent my personal brand […]. This concept also applies to expertise. My expertise is rented, and so I maintain my understanding of what it’s worth, and what is current on the open market.
Coverage Is Not Strongly Correlated with Test Suite Effectiveness - Greg Wilson
Coverage is not strongly correlated with test suite effectiveness (PDF) - Laura Inozemtseva and Reid Holmes, Proceedings of the 36th International Conference on Software Engineering
Wilson continues doing the important work of highlighting key empirical software engineering studies - in this case the work of Inozemtseva & Reid, who found a surprising result in an interesting way.
We had a “random” item about mutation testing in #57 - testing effectiveness of test suites by making random changes to code and ensuring at least one test fails. Here, Inozemtseva & Reid found that (sure enough) larger test suites caught more bugs - but apparently it’s the size of the test suite (e.g. number of tests) that is important; code coverage of the suite only tended to matter to the extent that large test suites were correlated with high coverage. Wilson has more details, and of course the paper itself
Ship / Show / Ask - Rouan Wilsenach
We’ve talked about pre-commit vs post-commit reviews in #34 - post-commit being something of an alternative to PR review. Changes that past CI testing get committed, so that developers aren’t blocked by waiting for review, and commits are reviewed later. (Obviously this incentivizes a large test suite!)
Wilsenach suggests that you don’t have to have a culture where it’s either/or. In the “Ship/Show/Ask” model, changes can be simply made without review (Ship) or post-commit review (or at least communication) happens for changes (Show) or pre-commit review happens (Ask), depending on the situation.
In practice, most of the research software development teams that I’ve seen have a “mostly-Ask” culture, but even there, we usually do in practice have an Ship/Ask model - no one requires PR approvals for fixing typos in documentations or the like. Would it be beneficial to extend the boundaries of what is permissible to “just Ship”? With “Show” for bigger changes that one things it would be useful to communicate?
What do your teams do in terms of review - pre, post, a mix?
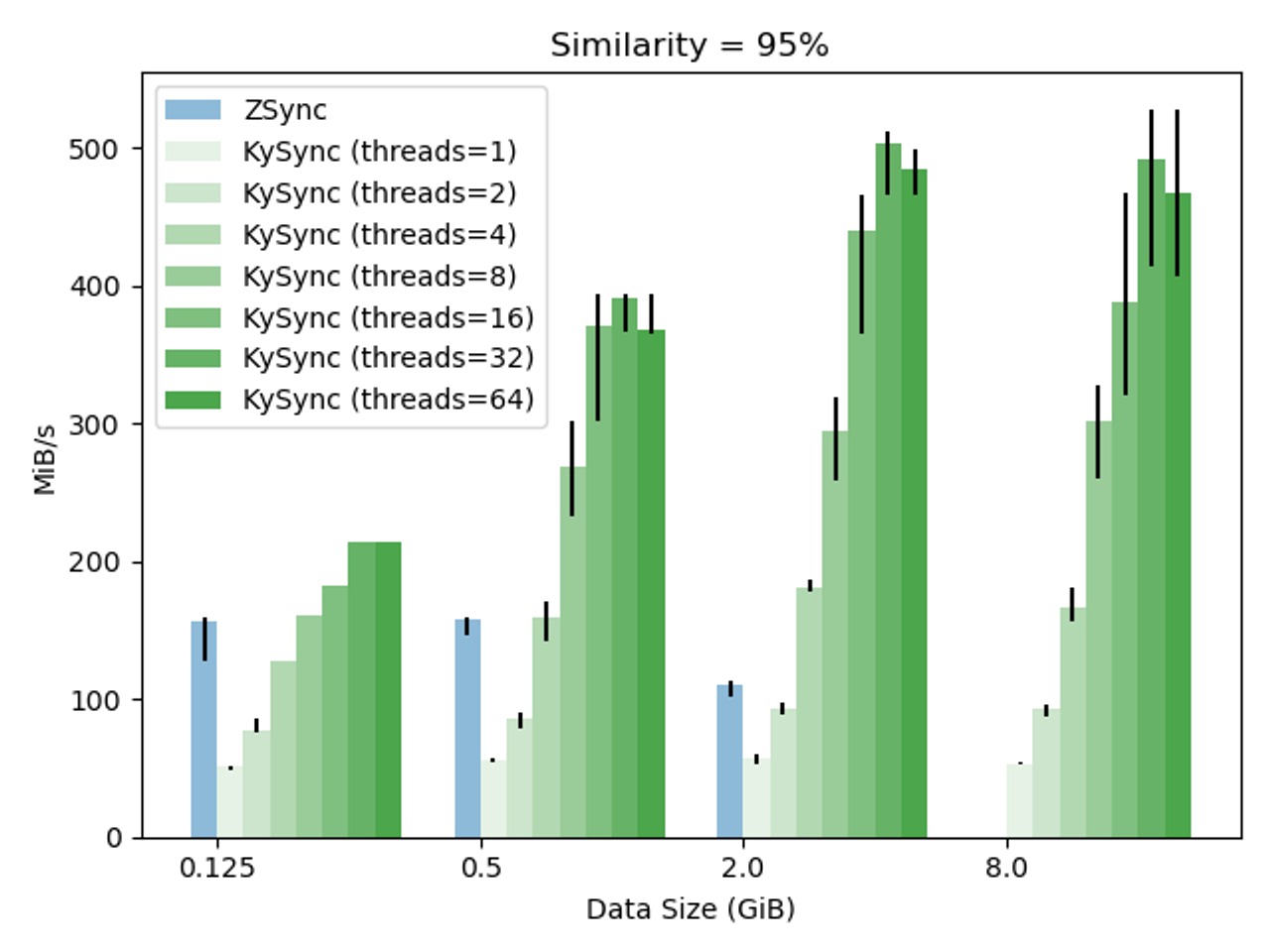
KySync - Kamen Yotov, Ashish Thakkar, Chaim Mintz
Rsync is a venerable peer-to-peer program to help changing files stay synced between machines, which inspired later tools like Unison. Rsync allows sending only files or blocks of files that have changed.
KySync is a complete rewrite - taking advantage of modern C++ and threading - of Zsync, a tool I hadn’t heard of, which takes the rsync approach and turns it into more of a client-server framework for distributing large amounts of data. Whereas rsync has the server do much of the work necessary to serve the data, Zsync pushes that to the client (making it easier to serve large amounts of slowly-changing data).
KySync performs significantly better than zsync, particularly for large amounts of similar data, and can take advantage of large numbers of threads, as shown below:
Reproducible, scalable, and shareable analysis pipelines with bioinformatics workflow managers - Laura Wratten, Andreas Wilm & Jonathan Göke. Nature Methods Perspectives
Nice to see workflow managers becoming so mainstream that they’re making the perspectives section of journals like Nature Methods. Wratten, Wilm & Göke give a great overview of the why’s and current what’s of workflow systems as used in bioinformatics analysis pipelines.
Serving Netflix Video at 400Gb/s on FreeBSD (PDF) - Drew Gallatin, EuroBSDCon 2021
These are the slides of a talk given by Gallatin at last week’s EuroBSDCon.
We tend to think of obsessing about memory bandwidth and NUMA domains as being exclusively the domain of HPC and big research computing, but it’s really not - no one wants their compute to be unnecessarily bottlenecked. Here, Gallatin talks about the process of getting data from disk out to the network as quickly as possible, on 32-core AMD EPYC Rome systems.
Data is pulled off of disk into memory via RDMA, encrypted (TLS) by the CPU, written back to memory, and fed out the network card. In the worst case, each one of those hops goes over a NUMA link, completely saturating the 280GB/s Infinity fabric.
Gallatin walks through improving, this, first through network-centric siloing - keep everything on the NUMA node associated with the network card. Then using kernel-bypass TLS in the NIC cards, drastically cutting CPU ↔ memory bandwidth requirements (and walks through how the smart NIC handles this), and playing with relaxed ordering of PCIe operations. There’s some interesting comparisons to Ampere Alta ARM boxes, and Ice Lake Xeons - and, familiar to anyone who has given a talk on their scientific work, an allusion to an experiment that couldn’t be done because of a last-minute delay.
Tammy Bryant Butow on SRE Apprentices - Thomas Betts, InfoQ
Advice for Tech Workers to Navigate the Most Heated Job Market of All Time - Gergely Orosz
It’s difficult to hire, especially senior people, for new-fangled roles such as anything involving cloud, deployment, web technologies, or anything security related.
In the first article, Butow talks with Betts about how her team bypassed this problem by hiring people for six-month apprenticeships in site reliability engineering, and keeping on those who succeeded - with the others leaving with six months of training in an extremely hot field.
Butow’s team was at Dropbox, which is sizable, but notably she was hiring for the databases team within Dropbox, which was at the time only four people. So this isn’t necessarily limited to being something only some huge team can handle. Particularly if paired with peer teams across an institution, this would be a relatively doable.
InfoQ articles lead helpfully with a Key Takeaways section which I’ll copy verbatim here:
Note that this requires real work, with a real thought-out curriculum and mentoring support, and onboarding into increasingly larger tasks.
In Orosz’s case he’s giving advice to people in tech about the current job market (spoiler: if more money is something you need or want, you should start looking for a new job). But, relevantly to Butow’s interview - the only area that this is not true is junior employees, because (from Orosz’s perspective) training up juniors is still hard and labour-intensive in a mostly-remote world. This is a place where research computing - often embedded in institutions dedicated to education! can shine and take advantage of their strengths.
7th Annual Unified Communication Framework & Annual Meeting - 30 Nov - 2 Dec, Submissions due 1 Nov
UCF is a group for “Collaboration between industry, laboratories, and academia to create production grade communication frameworks and open standards for data-centric and high-performance applications” and they coordinate development of things like UCX (and various bindings to it). Topics include UCX, OpenSNAPI, Unified Communication Collectives, tool development on top of that stack.
IEEE Edge 2021 - 18-20 Dec, Guangzhou China, Papers due 1 Oct
Hence, the 2021 IEEE International Conference on Edge Computing (IEEE EDGE 2021) aims to become a prime international forum for both researchers and industry practitioners to exchange the latest fundamental advances in state of the art and practice of Edge computing, identify emerging research topics, and define the future of Edge computing in the field of Computer Science and Electronic Engineers.
Topics of interest include architecture, service & software, platform & service for edge computing, as well as applications.
35th Annual European Simulation and Modelling Conference - 27-29 Oct, Virtual, CEST time zone, € 510 - 610
This three-day conference covers methods and applications of simulation and modelling - and analysis of the simulations - particularly in an industrial context.
Heads up that Let’s Encrypt original root certificate is expiring at the end of the month and some older clients without updated certificate bundles will probably break - although Let’s Encrypt has tried their best to make sure that, e.g., old Android devices that are no longer being updated will still work.
Fun riff on “infrastructure as code” - infrastructure state as data, infrastructure change/queries as code, and that code is SQL.
Like Windows Subsystem for Linux, but Windows is too newfangled for you and you never really got the hang of it? Introducing DOS Subsystem for Linux.
A fairly comprehensive list of 101-level Kubernetes Best Practices.
Paper in Scientific Reports finds for students learning Python in 10 45-minute sessions, language aptitude better explains speed of learning, programming accuracy, and post-test knowledge than math aptitude.
Using an obscure block-device I/O tracing package blktrace to image mounted disk volumes while they are being modified.
This is pretty cool. Use AWS Identity federation to allow GitHub Actions to do assume IAM roles (for deployment, CI/CD) without storing any secrets in GitHub.
A skeptic comes (partially, grudgingly) around on Python 3.10’s structural pattern matching.
Learn why git is the way it is by building a manual version control system with zip, diff, and patch.
Remembering the first real linux distributions of 1992.
Here’s an ambitious project - a from-the-ground-up rewrite of TeX called SILE, now with math.
There was a pretty noticeable performance regression in Linux 5.15 but it looks like a fix is on its way.
Been thinking of creating a personal GitHub readme page? Want to put some cool github stats widgets on it?