jonathan@researchcomputingteams.org
Happy October!
There’s a couple of articles in the roundup this week on professional development and career paths for those in research computing & data - and one of them even emphasizes professional development for managers.
We have a long way to go, but there’s widespread recognition that our profession needs to grow, and slowly growing recognition about the resources that will take. Even, finally, for us managers or team leads.
The weird truth is that the research world greatly undervalues training - it’s just expected that everyone will learn on their own. But from what resources, for research computing and data management? And when are we supposed to take the time to learn? We still need some help.
As potential managers, we have a lot of advantages - the flip side of that downside is that there’s a strong “growth mindset”, believe that people can grow; we’re comfortable with uncertainty; we’ve learned how to be good coaches and communicators in collaborations; we have technical skills and a vision. We have most of the advanced management skills at some level - but no one has ever taught us the everyday basics.
I’ll keep beating that drum, and as a community we can help some of these efforts take off and provide other teams with the resources they need.
Anyway, on to the roundup!
Research: Informal Leadership Comes at a Cost - Chia-Yen (Chad) Chiu, Jennifer D. Nahrgang, Ashlea Bartram, Jing Wang, and Paul Tesluk, HBR
It won’t surprise you to learn that leading and managing takes a lot of time and energy, and sometimes comes at a cost of some good will. But if you have a formal leadership role, you at least have the authority of role power to back you up, and it’s your main job, not taking you away from other tasks.
But if you are lucky enough to have informal leaders on your team who are taking on responsibilities and doing the glue work of multiplying a team’s efforts, they’re not so lucky. The leadership work takes time and energy, causes some friction with team members, but they don’t get a pay bump, titled authority, or (typically) time away from their IC duties.
And we often put good team members in this position on purpose, to give them the opportunity to take on more responsibilities and grow their skills. We’re doing it for good reasons, which is fine, but it’s important to recognize the costs and support them.
Chiu et al. suggest:
and supporting your informal-leader team members by encouraging them to stay aware of their needs and energy levels, and helping them out when they need it (by taking work off their plate or adding support).
Advancing the Workforce That Supports Computationally and Data Intensive Research - Patrick Schmitz, Scott Yockel, Claire Mizumoto, Thomas Cheatham, Dana Brunson, Computing in Science and Engineering
In #79 we mentioned an NSF grant on Strategic Tools, Practices, and Professional Development for Advancing Research Computing and Data. In this paper, the investigators give a great overview of the need for research computing and data personnel, real professional development opportunities, the very different requirements from higher ed IT, and the need for a career ladder on the individual contributor path. Newsletter readers won’t be surprised by the thrust of the paper, but it may be very useful for advocating, and it’s worth a read - there are great tidbits, e.g.:
researchers in the social sciences, for example, are using as much computing resources as physicists did ten years ago
In an April 2017, CaRCC survey of RCD professionals at over 150 universities, colleges, and government labs, professional development was identified as the top priority.
I greatly like the approach taken here of considering research computing and data as a whole with multiple facets. And there’s even a call for education managers for both staff and managers!
Low-code contributions through GitHub - Isabela Presedo-Floyd, Mars Lee, Melissa Weber, Mendonça, Tony Fast, Quansight Labs
Interesting experience getting people who wouldn’t normally code to make contributions to a project via github. In this case, the effort was around alt text for images (including scientific diagrams!) for a project, based on pull requests, but I could imagine it working well for documentation, sourcing diagrams, or other contributions.
The team’s process was:
Github’s web interface is pretty approachable (with some guidance) for making these kinds of contributions - it’s good to see that it works well.
Guides for Managers - Software Sustainability Institute
This is a resource I hadn’t seen until Better Scientific Software pointed it out - a collection of guides for research software development managers, including starting and improving a community for your product, recruiting a champion or student developers, funding software and developers, and more. The guides are short and come with links to other resources. They take a “focus on the basics” approach that readers of this newsletter would likely appreciate. Overlapping sets of guides for researchers, managers, and instructors are also available.
How late integration inflicts wicked problems on your Scrum Teams - Todd Lankford
This one hits close to home, because our team is now in month number… well, let’s not dwell on details, but our team has been dealing with this for a while now, and it’s my fault. I assigned a big chunk of work without breaking it down, it turned into a massive long-lived branch form hell, and a number of important efforts are blocked on it.
Had I taken action earlier it would have been painful but straightforward to clean up, but now there’s no way out but through.
Lankford points out three problems that I can personally attest to:
Anyway, don’t be like me, take Lankford’s advice and prevent this situation from happening in the first place, and if it does (a) fix it, even if it means throwing out work and (b) fix what caused it in the first place (in my case, assigning large-scoped un-groomed work) so it doesn’t happen again.
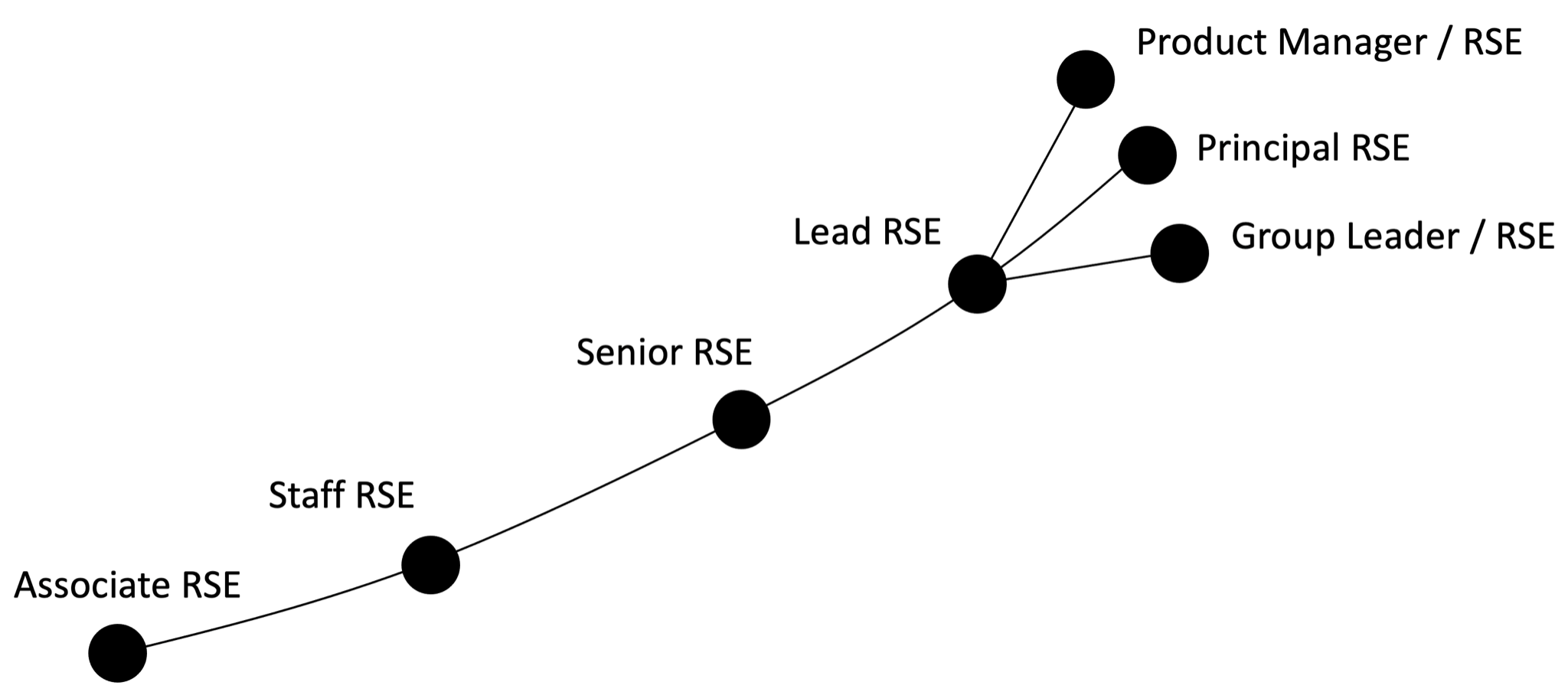
Senior level RSE career paths (with an s) - Daniel S. Katz, Kenton McHenry, Jong S. Lee
In the spirit of Shmitz et al.’s call for a career path for RCD individual contribitors, Katz, McHenry, and Lee describe a career progression for research software developers, starting with associate, staff, then senior research software engineer (RSE). Then there’s a bit of a step change to Lead, which I think is pretty well described here:
Some of these roles can include some mentoring and leadership, and at some point in technical progression, this becomes a key capability. For the purpose of this post, we’ll call this the Lead RSE level.
At that point the proposed ladder goes through a hypothetical fork into Product Manager, Principal RSE, and Group Leader, although the authors don’t actually have PdM or Principal RSE roles at their institution, so the discussion becomes less concrete at that point.
What I like about this article is the recognition of the desirability of separate product/people/technical leadership paths past a point, and discussion of a couple of anonymized case studies - but topping out before Lead.
A gap, as with much of the RSE discourse, is the focus on software as a silo completely disconnected from data or systems - certainly by the senior RSE level this would start to come into play.
Something else kind of discouraging: even a great and storied institution (NCSA) that knows the importance of research computing takes too unseriously training and mentorship around leadership and management. There is no training plan for management or technical leadership, not much recognition that that’s a problem, or even a suggestion of what that might look like. A group leader might get 20%(!!) of non-project-funded time to do everything not-directly-chargable, including management, and we’re not told how much a lead would get for technical leadership but it would presumably fall in the somewhere between 5% and 20% time that has to go to anything not directly chargeable to a project.
If you take your ICs time and skills seriously, a vital way to invest in them is to give them managers who know what they’re doing, and have the time to do it!
Announcing Cloudflare R2 Storage: Rapid and Reliable Object Storage, minus the egress fees - Greg McKeon, Cloudflare
Cloudflare is going from being a content distribution network (CDN) to a “cloud at the edge” like Fastly or Fly.io but with an AWS-like approach to delivering functionality in discrete composable products. This week it took direct aim at AWS, with “R2”: an S3-compatible storage layer, for a flat $0.015/GB/month, and with free operations on the data in the “single digit requests per second range”, and zero-cost egress (e.g., downloads),
Readers will know that I’m optimistic about edge computing and IoT for, e.g., large-scale data collection. But distributed object storage with no charges for data access by users could be really interesting for research data management and distribution. Just a week ago someone on the team was blocked because another team used GitHub LFS to distribute some sample data with their code and they exceeded their free-tier LFS download quota.
CDNs like Cloudflare know a thing or two about putting resources up for people around the world to download, and I’m really curious to see what research data distribution teams take advantage of this.
A friendly, non-technical introduction to differential privacy - Damien Desfontaines
A list of real-world uses of differential privacy - Damien Desfontaines
For sensitive data, as we’re being increasingly asked to handle in research computing and data, differential privacy is a mathematically principled way to release results from a dataset - or maybe even a representation of the dataset itself - while giving clear privacy guarantees.
Desfontaines has updated his very clear series of explanations on differential privacy, including a list of real-world uses that he knows of. Most are for learning or releasing of perturbed datasets; there’s only one use case in there now that supports interactive queries.
SRE deep dive into Linux Page Cache - Viacheslav Biriukov
In #92 we talked a little about mmap vs direct file I/O from the point of view of software development and data analysis. To really compare the two approaches, though, you need to have a sense of the differences of the code paths (e.g. the filesystem) - and where the code paths converge (the page cache).
Biriukov gives a lovely overview of the page cache and its uses, from the point of view that might have to debug mystifying performance (or even, rarely, correctness) issues that might arise. He gives some theory, walks through some basic I/O operations with strace to see what’s happening at the system call levels, and a variety of tools - vmtouch, /proc and /sys to see what’s happening, explains how pages are evicted, and in passing gives a nice overview of cgroups, page faults, vm.swappiness, and more. There’s also hints about a section about Direct I/O vs io_uring but it’s not finished.
This is definitely worth a read if you want to understand either virtual memory or the post-filesystem side of file I/O a bit better.
Are SSDs Really More Reliable Than Hard Drives? - Andy Klein, Backblaze Blog
Continuing the storage theme - Backblaze, which regularly issues quarterly Drive Stats reports on the reliability of the drives they use, hasn’t been using SSDs for as long as HDDs - so their HDD/SSD comparisons look like HDDs fail much more often (because older drives fail more often).
But when they look at SSD vs HDD boot disks of the same age, they find that they fail within the confidence intervals; about 1.05% annual failure rates for SSDs vs 1.38% for HDDs.
Klein says that there’s some evidence that for young drives (< 14 months) SDDs fail less than HDDs, but beyond that it’s a bit of a wash. More data will come in over time.
Looks like this week is AWS week in the newsletter in this section - sorry about that, but these were the most interesting posts I saw…
Security features of Bottlerocket, an open source Linux-based operating system - Jeremy Cowan, Sai Charan Teja Gopaluni, and Vijay K Sikha, AWS Open Source Blog
If your team is thinking of providing a system for users to run containers on, it’s interesting to see how AWS has locked down the OS they use for things like their EKS (kubernetes) or ECS (containers). Bottlerocket is the Linux distribution they use, and it is stripped down and secured in many different ways:
Running the Harmonie numerical weather prediction model on AWS - Jacob Poulsen and Karthik Raman, AWS HPC Blog
For one realistic-ish weather prediciton benchmark workload, AWS’s Elastic Fabric Adaptor plus Scalable Reliable Diagram gives comparable to or better performance on-prem Cray Aries interconnects, and everyone on HPC twitter was pretty mad about it. (Also on twitter, David John Gagne shared similar experiences for the US GFS model by Maxar, and some experiments with ECMWF).
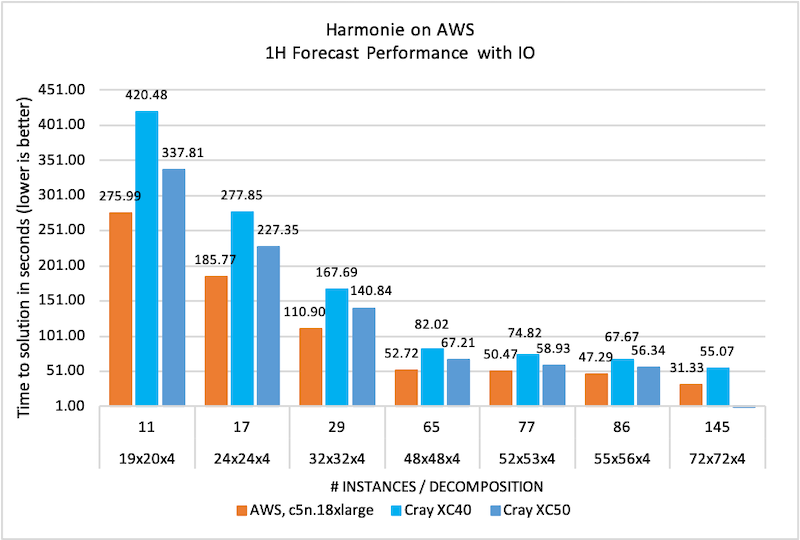
There are valid concerns about single-core performance mismatch - newer AWS c5n vs the older Crays and Intel compiler versions - so keep that in mind. But to my mind the interesting thing is the networking comparision as the number of nodes scales, and improving single-core performance would tend to put downward pressure on scaling, not upward. It doesn’t look to me like the AWS relative scaling results are falling notably by 86 nodes (though I’d love to see that 145 number for the XC50).
I think this is consistent with some other results we’ve seen here - for some realistic workloads, AWS’s specialized transport over non-specialized fabric seems to be comparable to “HPC networks” out to a couple racks. That doesn’t mean there aren’t workloads that do need Inifiniband or moral equivalent at smaller scale, nor that this extends out to huge scales; it’s just a data point for consideration within the wide range of use cases research computing supports.
Welcome to the Amazon Genomics CLI - AWS
Interesting - an open source (but assumes AWS) CLI for running workflows written in WDL or Nextflow (two common ways of describing workflows in bioinformatics) on AWS. Configure your context and specify instance types in a config files and then just “agc workflow run workflowname –context contextname”. All the work of setting up a Cromwell or Nextflow runner for you is done behind the scenes.
I’m struck by how much effort the commercial cloud companies are putting into making it easier for researchers to run their complex workflows, especially compared to the hoops we typically make researchers jump through.
KubeCon + CloudNativeCon North America 2021 - 11-15 Oct, $75 Virtual, $150-1,650 on site (Los Angeles)
If you’re at all interested in Kubernetes or cloud native, KubeCon/CloudNativeCon this year has a substantial virtual presence. Virtual is free or $75 for the all-inclusive ticket - and on-site is $150 for academics.
There’s two days of workshops (including getting started with Kubernetes, eBPF, or Kubernetes for airgapped environments), project open hours for efforts like Help, NATS, CRI-O, SPIFFE/SPIRE, Fluentd, Open Policy Agent, and others. Talks cover everything cloud native.
Graphical User Interfaces for Research Software - 26-28 Oct, Free
Imperial College London RSE team is putting on their third and final round for the year of GUIs for research software - one day on UI design and wireframing, one day on GUI toolkits (particularly python), and then one day of hackathon. Slides and recordings of the videos are available on the website if you just want to see what they cover.
Want the GitHub Copilot AI-generated code experience, but you’re in ops and mainly work in the shell? Great news - zsh_codex is here.
I recently set up SPF, DKIM, and DMARC for the researchcomputingteams.org domain, and it was a huge pain (and to this day I’m not sure I got it quite right). If you use Cloudflare for DNS, they have a wizard that will help.
Relatedly: I figured out how DMARC works, and it almost broke me.
Nota, a framework for making papers (and other explanations) more readable by adding interactive functionality and browser capabilities, rather than limiting to what’s possible with printed PDFs.
An overview of Gopher today - as late as 1994 I was pretty sure the web was a fad and that Gopher was the way things were going.
Cool performant react library for displaying multi-variate data on a global map: code and demo site.
SQLime - a sql-in-the-browser version of, e.g. JSFiddle or codepen.
Learn more about assembly, x86 calling conventions, and Python internals by writing a Python extension in assembly.
Instead of crontab, you could always use - sigh - systemd. Systemd timers, in particular.
Using an environment-modules style approach to handling having a large number of libraries available for JupyterHub environments in kubernetes. Old ideas never really die, they just get used in new ways.
Rust versions of *nix utilities seem to fail fuzz testing at roughly the same rate as the classic C utilities - which, depressingly enough, seem to fail at rates only modestly better than they did in 1998.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
About This Newsletter
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
This week’s new-listing highlights are below; the full listing of 159 jobs is, as ever, available on the job board.