jonathan@researchcomputingteams.org
Hi everyone - Happy New Year!
Here at RCT HQ, we’re slowly getting back into the swing of things after a long and relaxing holiday break - I hope it was relaxing and refreshing for you, your close ones, and your teams as well.
Since last we spoke, the big RCT-relevant discussions online have been about the aftermath of the Log4j fiasco, which was so big and had such large impact that in the US, the Federal Trade Commission as well as the national security apparatus have gotten involved.
Leaving the security aspects aside, the fundamental issue of scandalously under-resourcing the maintenance of underpinning open-source software is one which has been brought to the forefront, with even policy makers now well aware of the problem. Useful software will get used, often in unpredictable ways - that link takes you to a Google security blog post describing how 8% of Maven Central packages use log4j, but only 1/5 of that is of direct usage, the rest being indirect use by a dependency of the package, or a dependency-of-a-dependency-of-a-dependency. But there’s no robust mechanism for making sure the foundational work that underpins the flourishing ecosystem is supported. That, coupled with the high-profile bricking of faker.js and colors.js, have made the questions of what the broader community owes to foundational software maintenance, and what (if anything!) foundational software maintainers owe to the community, a central topic.
Of course this has long been an issue and discussed, in Research Computing and Data communities and in the Open Source community in general - The New Stack had an article explaining, correctly, that Log4j is one big `I Told You So’ for open source communities - but this very high-profile issue with huge consequences, along with a number of articles on the burden of maintaining open source packages, has brought it to the forefront in a way that even decision makers who wouldn’t normally wrestle with these issues are now confronted with.
So for the coming few months, connecting the needs of supporting research computing with Log4j will be an effective way of raising the issue with certain decision makers who might otherwise not be sympathetic - or at least, may not understand first-hand the urgency of the problem. Research funders want to fund innovative and cutting-edge work, and this will be an effective shortcut for reminders about the necessary preconditions for the glamorous results.
The preconditions of course include support of the people that work on software, data management, systems for research computing and data, and one of the ways to do that is to develop and inventory career pathways for these experts. Our colleagues at the Campus Research Computing Consortium (CaRCC) Career Arcs Working Group have a 15-minute survey that they’d like as many research computing and data team members as possible to fill out describing their career arc to date and what they’re looking for in next steps; filling that out will help inform the development of career pathways at member (and other) organizations. It would help if you could fill it out; in this newsletter we focus on supporting those of us in or considering moving into leadership and management roles in Research Computing and Data (RCD), and it would be important to have that perspective reflected in the surveys, but all pathways of interest really need to be highlighted.
With that, on to the round up! I’ve highlighted a few of the most interesting articles of the past weeks below with pretty short summaries.
Why We Need to Think of the Office as a Tool, with Very Specific Uses - Tsedal Neeley and Adi Ignatius, HBR
As we get ready to enter the third calendar year of the COVID-19 pandemic, it’s pretty clear that research computing teams’ relationship to the office and campus has changed in a way that will stay changed for the rest of our careers.
That doesn’t mean that a shared office has no place in our plans any more - and certainly campus matters! - but I think it’s pointed out to all of us that we were both leaning too heavily on being in person to avoid certain communication problems, while somehow also failing to take full advantage of the opportunities that being co-located with each other and with the broader research community provided.
This article is an interesting nuanced discussion between Neeley and Ignatius, but I think the most insightful and productive idea is right there in the title - the office is a tool, like slack or google docs or work-issued laptops, and it’s for us in our own local contexts to decide the best things to make with that tool, for our teams and for the communities we serve.
Handling Talent Fear - Aviv Ben-Yosef
With the tech hiring market red-hot, I know one manager who has exactly the talent fear Ben-Yosef describes here; they feel unwilling to be too directive or give too much feedback or coaching to their team members for fear that they leave. Yes, people can leave, and while they are on the team, it’s your duty to them and to the team as a whole to give them the feedback they need to get better and for the team to work together effectively.
If you find that challenging even in other times, in #83 we had a good article, A Manager’s Guide to Holding Your Team Accountable by Dave Bailey, about building accountability within a team, and we’ve covered a number of articles on giving clear feedback and coaching. There’s a good recent article at First Round Review by and Anita Hossain Choudhry and Mindy Zhang, The Best Managers Don’t Fix, They Coach — Four Tools to Add to Your Toolkit on coaching for addressing performance growth.
Tech 1-on-1 ideas & scripts - Rob Whelan
Here are some scripts or ideas for discussions for one-on-one meetings with team members, broken up into four categories of situations:
They’re short reads but useful for clarifying your thinking before going into one-on-ones; certainly for new managers and it’s always worth refreshing on the basics.
Managers should ask for feedback - CJ Cenizal
Cenizal makes what should be an uncontroversial - but relatively uncommonly followed - point that managers should be routinely asking for input on their own behaviours and leadership from their team members. This is much more easily done if there are routine one-on-ones, if the ask for input is also routine (not necessarily every one-on-one, but frequent), and the manager has a habit of demonstrating that they take such input seriously and are comfortable talking about their weaknesses and missteps. All of this is prerequisite for getting better at being a manager, team lead, project manager, or any other kind of leader! In the article, Cenizal lays out the steps:
I’d add a final step, following up with the team member. It’s important to show that you’ve taken the input and what underlies it seriously, even if you don’t adopt their proposed solution wholesale.
Even the UK Parliament and The Register are hearing that research computing and data staff are absurdly underpaid.
Copy the Questions, not the Answers - Jessica Joy Kerr
When getting advice from others - about your job, or your career - people tend to jump into giving you the answers (“When I was in this situation, I did X; you should do X”) but those answers rarely translate to your situation. Kerr reminds us that you don’t want to copy others answers, but it may be very useful to copy the questions they asked themselves and their decision making process.
Navigating Your Career Towards Your Own Definition of Success - Miri Yehezkel
Your Action Plan to DRI Your Career - Cate Huston
There’s only one person in charge of your career, and that’s you - you’re the Directly Responsible Individual (DRI) in the lingo of Apple’s internal decision-making process. Huston spells out concrete steps to take in planning your next move; Yehezkel’s article talks more about figuring out what you want, and how to prepare yourself at your current position before taking those next steps.
A collaborative GIS programming course using GitHub Classroom - Berk Anbaroğlu, Transactions in GIS
Discord For Online Instruction [twitter Thread] - Sara Madoka Currie
Two different tools for teaching are outlined here:
In the first, Anbaroğlu describes using GitHub Classroom to support a course teaching GIS programming, where students are paired up randomly to write a QGIS plugin. The paper describes the structure and pedagogy of the course, using GitHub to coordinate interactions, the steps in creating an assignment, survey responses, and student satisfaction. Incidentally the paper includes a very nice table with links to eleven different comparable GIS programming courses, if you’re interested in seeing what other courses are covering.
In the second, Currie advocates for using Discord for online teaching - the argument being that its asynchronous-first approach makes it more flexible and accessible, while still allowing synchronous (or asynchronous) video calls, screenshares, etc.
Strong Showing for Julia Across HPC Platforms - Nicole Hemsoth
Comparing Julia to Performance Portable Parallel Programming Models for HPC - Wei-Chen Lin and Simon McIntosh-Smith
Automated Code Optimization with E-Graphs - Alessandro Cheli, Christopher Rackauckas
I got turned off of Julia in its first few years by a series of erratic product management decisions, but the language and ecosystem seems to have stabilized and continues to evolve.
In the paper by Lin and Macintosh-Smith, described by Hemsoth, Julia acquits itself honourably against OpenMP, Kokkos, OpenCL, CUDA, oneAPI, and SYCL in the case of a memory-bound and compute bound mini application, across a number of different systems (Intel, AMD, Marvell, Apple, and Fujitsu CPUs, and NVIDIA & AMD GPUs). It did pretty well for the memory-bound case (although it was 40% slower on the AMD GPUs); it did a bit less well on the compute-bound kernel, as it couldn’t support AVX512 on x86, and on the Fujitsu A64X it couldn’t reach high single-precision floating point performance. Still, it’s solid results against carefully written specialized code.
And there are cool things ahead - Julia’s Lisp-like code-as-data makes it very easy to write domain-specific languages in, or use for symbolic programming, or do custom run-time rewriting of code. It’s that that Cheli and Rackauckas write about in their paper (and is described accessibly in this twitter thread). The same rewriting tools that other application areas are applying to symbolic computation in Julia can increasingly be used on Julia code in JIT compilation, allowing for very cool optimizations - such as being able to flag that reduced accuracy is ok in a specific region of code, or specifying known invariants or constraints in a piece of code that a static analysis wouldn’t be able to identify.
An Honest Comparison of VS Code vs JetBrains - 5 Points - Jeremy Liu
This topic actually came up this week at work - the inevitable “just got a new computer, what should I install” question. This is a quick overview of VSCode vs JetBrains, and Liu’s points are consistent with my experience of the two ecosystems - basically, VSCode is an editor with IDE features and an enormous third party package ecosystem of integrations, and JetBrains products are full fledged (and so slower to start up) IDEs for particular programming languages. If you need sophisticated refactoring capabilities and super easy debugging in the set of programming languages JetBrains supports, it’s going to be hard to beat that with VSCode. On the other hand if you need a fast editor with a wide range of capabilities and tools for supporting just about any programming language anyone uses, JetBrains tools are going to seem a little clunky and limited.
Hermit manages isolated, self-bootstrapping sets of tools in software projects - The Hermit Project
This is somewhat interesting - Hermit is a Linux/Mac package manager of sorts (think homebrew, but with conda-like environments) but targeted specifically at providing isolated, self-bootstrapping, reproducible dependencies for a software project, for development, packaging, or CI/CD. For research software, which often “lies fallow” for a time between bursts of development effort, this could be of particular use. Integration into the SDKs of Python, Rust, Go, Node.js and Java amongst others are supported.
A reminder that Python3.6 is now officially past end-of-life.
Don’t Make Data Scientists Do Scrum - Sophia Yang, Towards Data Science
On the one hand, research computing and data projects, especially the intermediate parts between “will this even work” and “put this into production”, often map pretty well to agile approaches - you can’t waterfall your way to research and discovery.
On the other hand, both the most uncertain (“Will this approach even work?”) and the most certain (“Let’s install this new cluster”) components are awkward fits to most agile frameworks, even if in partially different ways. The most uncertain parts are basically 100% research spikes, which short-circuit the usual agile approach; the most certain parts you don’t want a lot of pivoting around. And both ends of the spectrum benefit from some up-front planning.
Here Yang, who’s both a data scientist and a certified scrum master, argues against using scrum to organize data scientists, whose work is generally firmly on the “uncertain” side of the spectrum.
The argument is:
This doesn’t mean agile approaches aren’t useful, but they need some grounding in the nature of these more research-y efforts. This is true of some research software development efforts, too. Models like the Team Data Science Process or CRISP-DM or the like are worth investigating - not necessarily for verbatim adoption for a research process, but for getting a bit more nuance and structure.
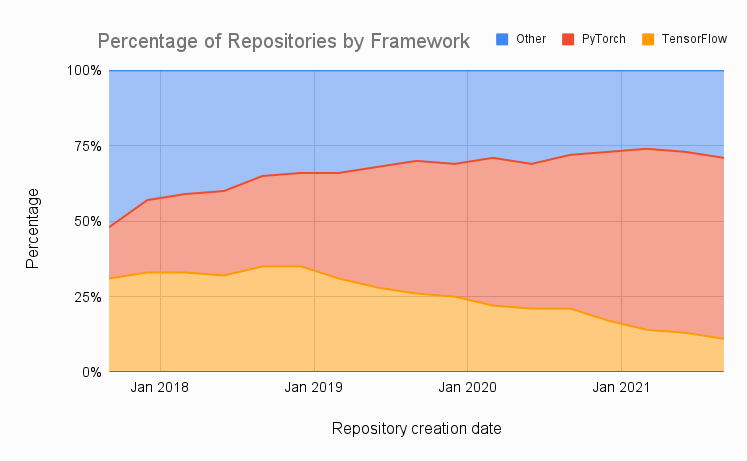
PyTorch vs TensorFlow in 2022 - Ryan O’Connor, AssemblyAI
Well, if we’re brave enough to wade into editor/IDE debates in Research Software, why not cover PyTorch vs TensorFlow as well?
O’Connor examines PyTorch vs Tensor Flow in three dimensions
O’Connor’s recommendation is that, if you aren’t already productively using one or the other, PyTorch is probably stronger for ML research unless you’re specifically using reinforcement learning, and that there are other frameworks of interest like JAX. For teaching, if models are the focus, PyTorch makes sense, while if software development around ML is the focus, TensorFlow makes the most sense. In Industry, he recommends TensorFlow unless you’re focussing on mobile applications where PyTorch Live is quite strong.
What would it take to recreate dplyr in python? - Michael Chow
Heck, let’s do R vs Python, too!
I don’t love R as a programming language, but it’s inarguably an amazing and productive environment for interactive data analysis. Compared to Python’s pandas-based ecosystem, it has fairly dumb data frames and puts the smarts in the processing tools, like the dplyr library, which lets you pipeline data operations in a functional-programming like way on the data frames. This approach is great interactively, easier to understand (at least for me), and can lead to real performance wins on large data sets with complex pipelines, at the cost of some other kinds of operations like data lookups.
This is a great article covering the differences, some of the costs of pandas’ approach (index copying, type conversions, non-composable grouped operations), and what it would take to allow dplyr-type pipelined operations in Pandas. He does this in the context of an attempted implementation of some of that functionality in the siuba package.
dsq: Commandline tool for running SQL queries against JSON, CSV, Excel, Parquet, and more - Phil Eaton, DataStation
Bashing JSON into Shape with SQLite - Xi Iaso
Ever wish you could run SQL on a JSON file, or JOIN a JSON file to a CSV?
There are an increasing number of these “sql on non-database-data-files” tools around now, and it’s great - it allows rapid and uniform(ish) analysis across datasets with modest amounts of data munging, and the SQL interface allows a nice on-ramp to eventually getting the data into a database.
I haven’t used dsq yet, but DataStation just open sourced it; it’s based on SQLite and the range of data file types supported (including currently nginx and apache log files) seems really handy.
Relatedly, since dsq makes use of SQLite, Iaso describes the use of SQLite’s JSON capabilities, JSON functions, and SQLite triggers to automate the process of munging JSON.
New Tool: Mess with DNS! - Julia Evans
Mess with DNS - Julia Evans and Marie Claire LeBlanc Flanagan
Here Evans outlines a terrific tool she put together for teaching and experimenting with DNS. Uniquely, as far as I know, it gives you a real subdomain on a real DNS server, shows a live stream of incoming DNS queries, lets you experiment in any way you like with (with two static IP addresses provided to use), and also has a set of increasingly sophisticated experiments you can walk through. The first link is the blog post where she describes both the tool and the process of building it, including tool choices; the second is the tool itself.
Publication of the Trusted CI Guide to Securing Scientific Software - Trusted CI
The Trusted CyberInfrastructure project has released its report and now guide into securing scientific software - and to some extent the systems they run on.
The guide covers the usual topics, but with specific focus on scientific computing: “social engineering”, classic software exploits such as you’d see on OWASP’s top 10 (injection attacks, buffer overflows, improper use of permissions, brute force, software supply chain) and network attacks (replays, passwords, sniffing), and gives guides on training, governance, analysis tools, vulnerability management, and using good cryptography.
For those interested in learning more, For those interested in hearing more, three’s a webinar focused on the topic of software assurance scheduled for February 28, 2022 at 10am Pacific / 1pm Eastern; free registration can be found here.
It’s Time to Talk About HPC Storage: Perspectives on the Past and Future - Bradley Settlemyer, George Amvrosiadis, Philip Carns, Robert Ross, Computing in Science & Engineering
In this open-access paper, the authors talk about the challenges of adapting HPC storage architectures to increasingly data-driven workloads, especially AI.
Developments in low-latency RDMA networks and NVMe storage help, but they argue that the storage architectures of the early 2000s still need updating, particularly the model of having a small number of big storage servers. And providing secure access while driving down latencies is genuinely challenging.
They argue for new approaches focusing on the entire data path - zoned data storage rather than block models, more distributed data, better use abstractions, and a revitalized HPC storage research community.
Kyoto University loses 77TB of supercomputer data after buggy update to HPE backup program - Dan Swinhoe, Data Center Dynamics
I think we all read about and winced at this one - an HPE software update deleted 77TB of data from backups, as correct “delete log files after 10 days” behaviour interacted with incorrect “update a running bash script which changed how variables were handled, resulting in undefined variables” behaviour. Worth considering as a tabletop exercise - if something like this happened, how long would it take for your systems team to discover it? What would be the next steps?
Run a Google Kubernetes Engine Cluster for Under $25/Month - Eric Murphy, The New Stack
If you want to play with a “real” Kubernetes deploy (e.g. not just on your workstation) without tying up local resources, Murphy describes running a single GKE cluster on Google cloud with 3 nodes, 6 cores, 24 GB ram, enough for a modest web application or CI/CD pipeline or the like, for under $1 USD/day by relying on spot instances and cheap regions but not requiring expiring free tiers (except for the GKE control plane, which is free for one cluster but not if you use more than one in the same account). Murphy provides a Terraform config in a GitHub repo.
AI makes it possible to simulate 25 billion water molecules at once - Matthew Sparkes, New Scientist
Extending the limit of molecular dynamics with ab initio accuracy to 10 billion atoms - Zhuoqiang Guo et al, ArXiv
Using AI-trained kernels for traditional HPC simulations continues to show a lot of progress; here are two related works demonstrating the use of deep-learning trained systems to model larger systems faster while still being recognizable as MD simulations.
If you have, or are thinking of starting, a practice of having team members who attend trainings come back and share what they’ve learned, the article Different ways to share learnings from a training event by Richard McLean may be of interest. There’s a lot to be said about having such a practice - it’s a good way to kick-start other knowledge-sharing practices within or across teams, and also just a good way to get people to practice giving educational presentations or training in front of a friendly audience.
The International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2022) - 12-14 Jan, online, Free
This three day free online conference includes technical talks on very large scale simulations, algorithms for simulations, system software for machine learning, performance evaluations, and workshops on resource disaggregation, ARM in HPC, and multi-physics problems.
1st International Workshop on Resource Disaggregation, in High Performance Computing (Asia Edition) - 14 Jan, Online
Held in conjunction with HPC Asia’22 above, this first workshop on disaggregated resources in HPC covers current (CXL) and emerging (photonics) technologies for disaggregated/composable computing.
Fundamentals of Accelerated Computing with CUDA C++ - 14-15 Feb, 13:00-17:30 EST, Virtual
The Molecular Sciences Software Institute (MolSSI) and NVIDIA have a series of limited-registration hands-on workshops - the next workshop with attendance still open is CUDA C++, and a following one in March covers scaling CUDA C++ applications to multiple nodes.
Fortran for Scientific Computing - 21-25 Feb, Online, EU-friendly timezones, €30-360, Registration due 23 Jan
Topics covered include
Argonne Training Program on Extreme Scale Computing - 31 Jul-12 Aug, Chicago area, Applications for registration due 1 Mar
Argonne’s extreme-scale computing training registration is open; due to limited enrolment, attendance is competitive; all costs are covered for successful applicants.
A lot of CFPs have come out over the holidays:
12th International Workshop on Accellerators and Hybrid Emerging Systems (AsHES 2022) - Colocated with IPDPS2022, 30 May - 2 June, Lyon, Papers due 30 Jan
Full (8-10pp) or short (4pp) papers are solicited for applications/use cases, heterogeneous computing at the edge, programming models, optimization techniques, compilers and runtimes, system software, and more.
4th Workshop on Benchmarking in the Data Center: Expanding to the Cloud - 2-3 April, Seoul, Papers due 31 Jan
Held as part of Principles and Practices of Parallel Programming 2022, 8-page papers on benchmarking systems are welcome, especially in areas of:
27th International Workshop on High-Level Parallel Programming Models and Supportive Environments (HIPS’22), 30 May, Lyon, papers due 28 Jan
Held as part of IPDPS 2022, this topic covers high-level programming for HPC-type applications, including high-level and domain-specific programming languages, compilers, runtimes, monitoring and modelling tools, etc.
DOE Monterey Data Workshop 2022 - Convergence of HPC & AI - 20-21 Apr, Berkeley and Online, session proposals due 31 Jan
From the call:
The meeting organizers are seeking speakers to give short (nominally 20 minutes) talks on progress, ideas, and/or challenges on AI/ML. We encourage talks from early career scientists and are prioritizing talks in the following topical areas: Scalable and productive computing systems for AI, Interpretable, robust, science-informed AI methods, Novel scientific AI applications at large scale, AI for self-driving scientific facilities
ExSAIS 2022: Workshop on Extreme Scaling of AI for Science, 3 June, Lyon, Papers due 1 Feb
Also part of IPDPS, this workshop focusses on extreme-scale AI for science. Algorithms, tools, methods, and application case studies are of interest.
36th ACM International Conference on Supercomputing (ICS) - 27-30 June, Virtual, Papers due 4 Feb
From the call,
“Papers are solicited on all aspects of the architecture, software, and applications of high-performance computing systems of all scales (from chips to supercomputing systems), including but not limited to:
34th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA 2022) - 12-14 July, Philadelphia, papers due 11 Feb
“Submissions are sought in all areas of parallel algorithms and architectures, broadly construed, including both theoretical and experimental perspectives.” A subset of topics of interest include the below, but see the CFP for the full list.
SciPy2022 - 11-17 July, Austin TX, Talk and Poster presentation abstract proposals due 11 Feb
Besides the general conference track, there are tracks in ML & Data Science, and the Data Life Cycle. There are also minisymposia in Computational Social Science & Digital Humanities, Earth/Ocean/Geo & Atmospheric sciences, Engineering, Materials & Chemistry, Physics & Astronomy, SciPy Tools, and for Maintainers (very timely).
RECOMB-seq 2022 - 22-25 May, La Jolla CA, Papers due 11 Feb
One of the premiere venues for algorithmic work in ‘omic sequencing has its CFP out - submissions (new papers, highlights, or short talks or posters) are due 11 Feb.
CCGrid-Life 2022 - Workshop on Clusters, Clouds and Grid Computing for Life Sciences - 16-19 May, Italy, Papers due 11 Feb
“This workshop aims at bringing together developers of bioinformatics and medical applications and researchers in the field of distributed IT systems.” Some relevant topics of interest are:
Supercomputing 2022 Workshop Proposals - 13-18 Nov, Workshop Proposals due 25 Feb
With SC21 barely over (and its in-person program still somewhat controversial), it’s already time to start thinking about SC22 half-day or full-day workshop proposals.
10th International Workshop on OpenCL and SYCL - 10-12 May, Virtual, Submissions due 25 Feb
Submissions for papers, technical talks, posters, tutorials. and workshops are due 25 Feb
14th International Conference on Parallel Programming and Applied Mathematics, 11-14 Sept, Gdansk and hybrid, Papers due 6 May
Papers are welcome covering a very wide range of topics involving parallel programming for applied mathematics.
You will shortly be able to use Markdown to generate and display architecture or sequence diagrams on GitHub in READMEs, issues, gists, etc using mermaid syntax.
Writing good cryptographic hash functions is hard! Here’s a tutorial inverting a hash function with good mixing but no fan out.
Mmap is not magic, and has downsides. Here’s a paper explaining its limitations particularly for databases.
Create neural network architecture diagrams in LaTeX with PlotNeuralNet.
It’s gnu parallel’s 20th birthday this month! Take the opportunity to say happy birthday to this extremely useful and very frustrating tool.
“Bash scripts don’t have to be unreadable morasses where we reject everything we know about writing maintainable code” has been a long-running theme of the random section of this newsletter - here’s a community bash style guide.
As has advocating for the under-appreciated utility of embedded databases. Consider SQLite, a curated sqlite extension set, and a set of sqlite utils.
And SAT solvers/constraint programing/SMT solvers. Here’s solving wordle puzzles using Z3, or the physical snake-cube puzzle with MiniZinc.
Use Linux but miss your old pizza-box NeXTStation? Use NEXTSPACE as your desktop environment.
Miss 80s-style BBSes and miss writing code in Forth? Have I got news for you. Maybe you could use this Forth interpreter written in Bash. Or this one which compiles(!) to bash.
A real time web view of your docker container logs - dozzle.
A visual and circuit-level simulation of the storied 6502 processor (Apple II, Atari 2600, Commodore 64, BBC Micro) in Javascript.
High-speed and stripped-down linker mold has reached 1.0.
If you write C++, you might not know that lambdas have evolved quite a bit since C++11, with default and template parameters, generalized capture, constexpr safeness, templated lambdas, variadic captures, and you can return lambdas from functions now.
Function pointers satisfying an abstract interface in Fortran, with fractal generation as an example.
A really promising-looking free course and online book on Biological Modelling by Philip Compeau, who was part of the unambiguously excellent bioinformatics algorithms coding tutorial project Rosalind and “Bioinformatics Algorithms: An Active-Learning Approach” book.
A quantum computing emulator written in SQL with a nice tutorial explanation of state vector representations and some basic gates.
A lisp interpreter implemented in Conway’s game of life.
Rwasa is a web server written in x86 assembler for some reason.
How graph algorithms come in to play in movie end credits.
I did the advent of code this year, and it has a genuinely lovely ad-hoc community built up around it.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.