jonathan@researchcomputingteams.org
Hi, everyone:
I’ve been thinking of jobs a lot lately, of course, for my own reasons and just through the effort of curating the research computing teams leadership job board. (The board has gotten a number of community submissions lately - keep them coming! I just check them for spam before accepting them).
A year and a half ago I posted my observations on the first 500 jobs posted to the board - we’re getting close to 1,500 now, and it’s worth taking a look to see what if anything has changed in research computing team leadership jobs.
There are some trends that have continued since the posting. The jobs in industry are growing vastly beyond what I would have imagined possible when I started in research computing in the 1990s. Rather than technical computing being a niche, it’s utterly mainstream now. There are a lot of jobs out there, and I don’t even bother posting generic “data science manager” jobs unless they’re connected to some real complex research questions - which happens a lot, whether it’s fraud detection or improving financial modelling or whether it’s supporting biomedical research. Some really fun-looking jobs that would probably feel a lot like working at a research computing centre keep coming up at consultancies – go visit a client and help them with their data science/data engineering/etc needs. There’s also a growing number of data science/engineering jobs at Universities that fall under the Provost/VP Operations rather than the VPR’s side of the house - Institutional Research, looking at (say) student success in support of the teaching mission.
Because of the growth in number of jobs, it is very much a candidate’s market out there. I’m seeing postings – especially for the traditional academic “director of research computing” jobs — stay open for cringe-inducing periods of time. A few in particular I’ve watched with vicarious embarrassment continue coming up in the listings for 8+ months. That’s a bad sign for us as hiring managers - the market for individual contributors is at least as tight - but it’s amazing news for us as individuals.
When I wrote that post in late 2020 it was just regulated industries like health/biotech or financial services that were developing data governance or other data management jobs, but now data management is popping up everywhere, whether it’s retail or logistics or anywhere else. These are being joined, again first in the regulated industries, by data privacy or data risk management jobs. Privacy-preserving data analysis jobs (and teams supporting same with software development) are also starting to be more common (and there’s a lot of cool research and technology work to be done there!)
I’m also (finally!) starting to see a lot of explicitly product management jobs in research computing, both academic and private-sector. You see it around data management — bundling and curating of data into real data products — but also in software development, especially around analysis pipelines for some reason.
Probably related to the growth product vs project thinking, I’m starting to see a lot of “delivery manager” jobs that would have been called “project managers” just a year ago. Projects are defined by having clearly defined start- and end-points up-front. “Delivery” jobs seem to focus on sustained, ongoing work, more appropriate for long-lived products.
These products that keep coming up often combine data, software, and systems one way or another. That really points to weaknesses around organizing by type of skills - the research software engineering movement, for instance - as the lines between software and systems in this DevOps, infrastructure-as-code era is very fuzzy; and as data grows more and more important, data skills are needed everywhere.
Especially for us as managers or leads, but especially for individual contributors as they grow their skills, it’s important to have a pretty holistic view of research computing and data and not try to break it up into silos. The growing number of data engineering jobs is a great example. That work often involves all three of software, systems, and data expertise. Data engineering is getting so broad and important that not only are there different sub-fields, in large organizations there are likely to be completely distinct data engineering teams doing different work. Trying to decide which of those jobs are “research software engineering” jobs and which aren’t is not a productive way forward, for those candidates or for us as a community.
Needless to say, the growth of remote jobs has been off the charts - especially in the private sector, although the academic institutions are gamely doing what they can to keep up (often hampered by institutional policies).
In other news, the new job is going well so far. It’s fascinating to see how differently communication works in different teams. Expectations around different media are completely flipped from how we thought of them at the previous job. After five and a half years in one position, it’s useful if bracing to be confronted with the fact that the way one did things was just a team preference, not some immutable fact of human behaviour.
Related to that, we have some articles kicking off the roundup this week reminding us of just that. We have to be ready to give up even good practices if we find that they aren’t working in our situation, and critically assess our approaches in light of how well they work. We’re working in science - that should come naturally to us! But it’s a lot easier to dispassionately study something else than it is to study ourselves and our outcomes.
With that, on to the roundup!
How to have the best Bad Meetings - Matt Schellhas
Structural Lessons in Engineering Management - Camille Fournier
Stop Repeating Yourself - Marissa Goldberg
We start off with three very different articles which drive home an important common point.
There are a lot of really, really good rules of thumb in management. New managers would do well to adopt them wholesale when starting out, and even experienced managers should default to them.
But. These rules are tools in the toolbox, used in service of larger goals. The purpose is to have an effective team of satisfied, productive, and growing team members supporting research. If you find that the usual best practices don’t work in some case, you shouldn’t hesitate to put a tool aside, and reach for another. New managers should require more convincing than experienced managers that something different is needed! But if something isn’t working, then change it.
In the first article, Schellhas talks about jettisoning the usually important best practices - agenda, minutes, etc - for his meetings. In his situation, the meetings are generally to decide on a specific singular thing, like solving a problem or getting to a next step. So he sets a clear purpose for the meeting, has someone at arms length from the problem involved in running the meeting, and that’s enough to focus the meeting successfully for his teams’ needs.
In the second, Fournier discusses another excellent rule of thumb - managers should have something like 7 ± 3 directs, maybe a bit more of fewer depending on the type of work - but points out either the rigidity or absurd levels of organizational churn that produces if it’s enforced too rigidly. It’s good to aim for, variations should be looked askance at. But hardcoding rules, even good rules, into as complex a system as human organizations can cause its own problems.
Finally, Goldberg points out that some rules should be followed but one has to be careful taking them too literally. We’ve talked here more than once about the importance of communicating the same idea repeatedly, to the team or stakeholders, especially about change. But that doesn’t mean repeating yourself the same way over and over again. The purpose of communications is to update the internal state of the people you’re communicating with. If the first communication didn’t “take”, doing it the same way again may not, either. So communicate the same idea repeatedly, yes, but use various approaches and methods.
Employees Are Sick of Being Asked to Make Moral Compromises - Ron Carucci and Ludmila Praslova, HBR
The last few years have made a lot of people question a lot of things in their day to day. This HBR article by Carucci and Praslova reports on a pretty widespread phenomenon that we can take advantage of. There are a lot of very talented technical personnel who are starting to be dissatisfied with improving click rates for online ads, or other lucrative but deadening activities common in tech firms.
The advice Carucci and Praslova offer isn’t really relevant to us. Whatever the various challenges of employment in research, we already offer meaningful work that people can be proud of. As long as we can keep our workplaces and team behaviours consistent with the open-minded discovery we want to support, we’re in good shape and have a lot of potential job satisfaction to offer.
Don’t Worry, You’re Not Wasting Your Mentor’s Time - Lara Hogan
Can’t agree with Hogan’s post enough. It’s worth finding mentors (multiple mentors, who have different areas of expertise) and consulting them often. I have a few semi-regular calls with research computing team leads, mentors, and others who sometimes have questions or are looking for advice. It’s a joy to speak with them. I sometimes offer perspectives or insights, and some fraction of what I share ends up being useful, but I get at least as much from these exchanges as I give.
We’re part of a wide, multidisciplinary community with diverse expertise and experience. Make use of it! Talk to local institutional or regional colleagues, send questions to the community by replying here, or join #research-computing-and-data in the Rands Leadership Slack. Leadership can get lonely, but it doesn’t have to be that way.
Sustained software development, not number of citations or journal choice, is indicative of accurate bioinformatic software - Paul P. Gardner et al., Genome Biology
The quote from the Results section sort of says it all:
We find that software speed, author reputation, journal impact, number of citations and age are unreliable predictors of software accuracy. This is unfortunate because these are frequently cited reasons for selecting software tools. However, GitHub-derived statistics and high version numbers show that accurate bioinformatic software tools are generally the product of many improvements over time.
I’m fond of saying that software isn’t “sustainable”; software is sustained, or it isn’t. This paper points out that software that is sustained tends to be more accurate than software that isn’t, even if that other software is highly cited.
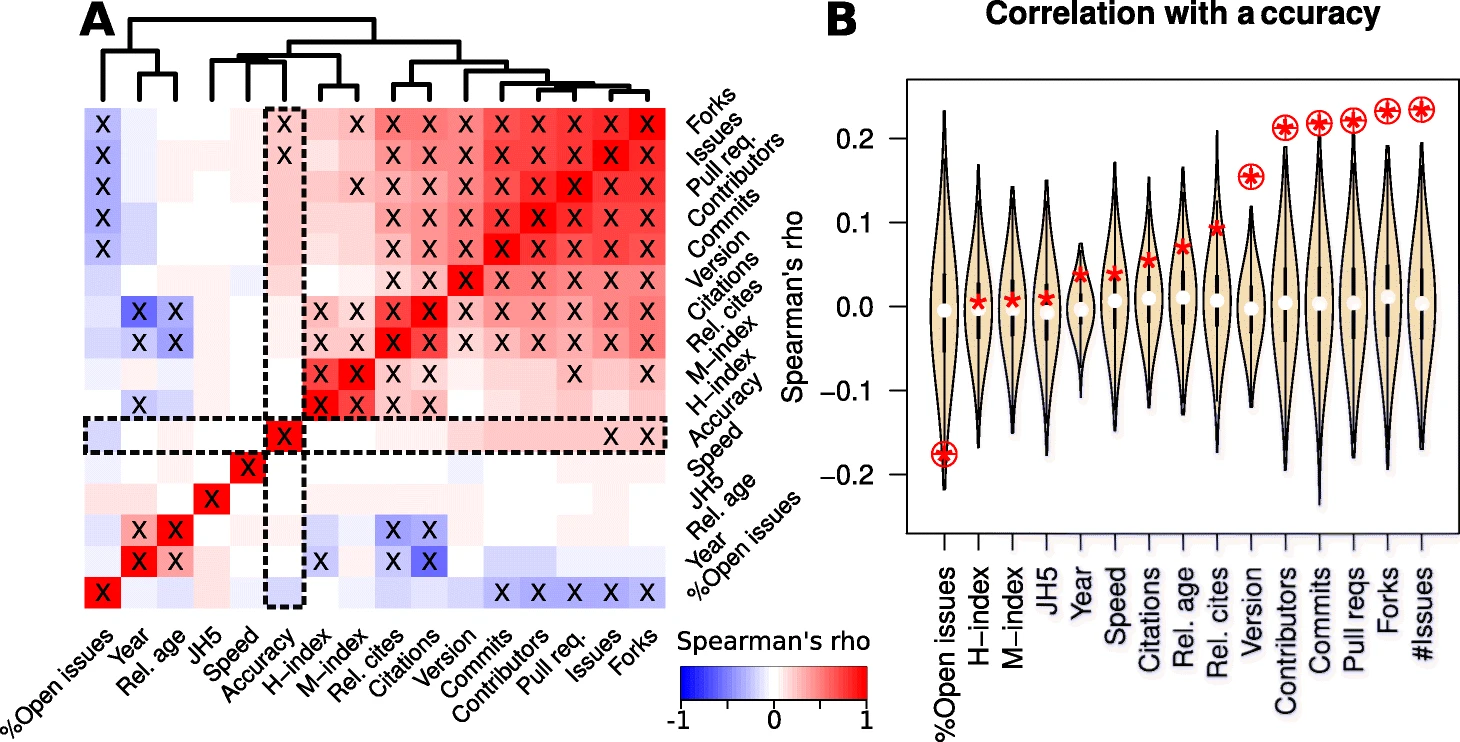
A second suggestion is that there may be a positive correlation between accuracy and speed of the software, probably because continued maintenance will tend to improve both:
We also find an excess of slow and inaccurate bioinformatic software tools, and this is consistent across many sub-disciplines. There are few tools that are middle-of-road in terms of accuracy and speed trade-offs.
Sparse arrays and the CESM land model component - Deepak Cherian & Katie Dagon, NCAR
The pydata ecosystem, and in particular fundamental pieces like xarray for labelled multi-dimensional arrays and dask for parallel execution, continues to grow in capabilities. One of the reasons for the success was that these tools have exposed and been built on well-thought-out APIs, which allows them to swap out implementations for different needs.
Here Cherian & Dagon describe how analysis of Community Land Model (CLM) outputs is made relatively straightforward using xarray (for labellng various components and dimensions, a la NetCDF), and sped up by using sparse arrays, swapped out for the usual dense NumPy arrays with very little difficulty.
Herding elephants: Lessons learned from sharding Postgres at Notion - Garrett Fidalgo, Notion Blog
pg-osc: Zero downtime schema changes in PostgreSQL - Shayon Mukherjee
Always love a good migration story. Here Fidalgo walks us through Notion’s process of migrating a huge Postgres database to shards. As always, a lot of the work is the careful, step-by-step migration. Notion’s steps were:
A lot of the writeup is about the design of the sharding, which will vary from usecase to usecase. An interesting idea I hadn’t seen before that does generalize was to define logical shards first. They logically sharded the data into 480(!) shards even though they were going to use many fewer nodes. The idea is that 480 has many many factors (it’s an abundant number) meaning they could relatively painlessly change the number of nodes they use over time.
In another Postgres-wrangling article, Mukherjee talks about one approach to zero-downtime schema changes using postgres shadow tables (usually for things like auditing), and his tool for automating the process, pg-osc (postgres-online schema change).
Nasty Linux Kernel Stack Overflow Flaw Found and Patched - Steven J. Vaughan-Nichols, New Stack
Oh, Snap! Security Holes Found in Linux Packaging System - Steven J. Vaughan-Nichols, New Stack
GitLab Critical Security Release: 14.8.2, 14.7.4, and 14.6.5 - Costel Maxim, GitLab
New week, new vulnerabilities. Two ugly Linux vulnerabilities - a remote exploitation and a local privilege escalation - but luckily under pretty limited conditions. The first requires the TIPC service running, and I don’t know many (any?) big systems using that; the second, a vulnerability in containment of snap, likely affects more workstations than clusters. Still, patch, and as always - be careful out there.
Also, if you’re hosting your own GitLab instance, I have questions! But also, there’s a critical security release that addresses a number of issues.
All New Repls are Powered By Nix - Connor Brewster, Replit
I’m not sure that Nix is ready, or suitable, for research computing systems, but the immutability of packages (with associated cachability), ability to roll back, and reproducibility are attractive. Here Replit, a collaborative online IDE service for 50+ languages, offers a pretty compelling use case for use of Nix. They use it when offering individualized but reproducible services directly to end users, knowing that you can always recreate it from scratch. There are definitely use cases in research computing that have similar needs!
Going Multipath without Multipath TCP - Ben Cox
Quick overview of multipath TCP and the problems in getting it working by Cox, and a utility for multipath UDP for faster transfers (in his case to tape) or backup link failover.
How to start using reusable workflows with GitHub Actions - Brian Douglas
If your team uses GitHub actions for CI and/or CD, and has several products using similar workflows, it may be useful to pull that workflow out into a reusable workflow, so it can be updated in one place and used in many projects. The good news is it can use if conditionals, secrets, multiple jobs, and logs each step - the bad news is that it can’t call other reusable workflows. The main difference is that the reusable workflow has a new on: workflow_call: trigger. Douglas explains how to use them, and the pros and cons.
How fuzz testing works in Go 1.18.
A video from 1989 from Thinking Machines on data parallel supercomputing.
Implementing traceroute with a bash one liner using ping.
Explaining Gödel’s incompleteness theorem with bash scripts.
Solving Sudoku problems with package managers.
It infuriates me that Google Drive - Google Drive - has such appallingly bad search that it’s hard to keep track of your stuff. Google-drive-to-sqlite fetches metadata for all your files in Google Drive and stores them to a local SQLite database.
Last week I mentioned that obvious seeming things are actually pretty hard to do well. Do you find yourself ever outputting integers from your code? Yes? Creating a fast implementations of that is bizarrely complex.
I feel like this one should come with a safety warning: The RCT Surgeon General strongly recommends against hosting your own mail server. But, if you want to see how SMTP works, here’s implementing SMTP from scratch in Go.
A programming language that keeps track of side effects to implement caching as a language feature - skiplang.
In Python, strings have to behave as if they’re immutable, but as an optimization CPython will actually mutate strings if it can.
Speaking of - create standalone, self-contained Python builds for integration with a larger package with python-build-standalone.
Want to play wordle natively, but you’re stuck on Windows 3.1? We got you.
Or you want to develop for the Sinclair ZX-Spectrum, but with VS Code and a modern devopsy CI environment? We got you there, too.
Oh, you’re all modern and fancy and want a state-of-the-art Windows 95-looking dev environment? Alright, there you go.
Nice collection of resources on security engineering.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.