jonathan@researchcomputingteams.org
Hi!
It’s been pointed out I have my view of the role of specialization in research computing teams seems a bit contradictory. I am very pro-specialization, but anti-siloing. Fair point! Let’s dig more into that.
No research computing and data team can do everything. It’s not possible. Pretending otherwise leads to unhappy team members and unsatisfied researchers. And as I like to point out, there’s already tonnes of computing things our teams don’t do for researchers. We don’t help them with their printers, or lay out designs of posters for conferences. So my advice is wherever possible — and it’s more possible than you think — is to add a few things to that list. To niche down into a specialization.
The most meaningful specialization is of the form of “we help [community] with [problem]”. One very effective way to do that is where community is a particular discipline (defined broadly). “We help wet lab molecular biologists with their bioinformatics analyses”. “We help social sciences researchers with their GIS software development needs”. “We help researchers with long term data retention needs affordably and reliably store and share their data”. “We help health scientists write and deploy desktop and mobile data collection applications”. “We help researchers new to quantitative methods with data science”. “We help researchers with web applications deploy, operate and maintain their application stacks”.
There are a lot of advantages of such a specialization:
A decent sized team could potentially have two or three of those specializations, aligned either along the community or problem axes, and still be sharply focussed. It starts to look like a core facility, which faculty, institutional decision makers, and funders all instinctively understand.
A significantly weaker and less meaningful form of specialization is, unfortunately, a little easier to fall into. It’s more inward looking and input based rather than focused on researchers and their needs. It’s to lean on the tools you use. To focus shallowly on the activities you perform. “We write C++ code for research”. “We run a cluster researchers can use”.
There are three big problems with this approach.
The first is with communicating your existence to researchers at all, much less attracting them as clients. Few researchers have a problem they think of as primarily a C++ problem, or a running-cluster problem. By and large, they have (say) functionality they want to add to a groundwater data analysis code, or the need to run an ensemble of simulation-analysis pipelines. Maybe C++ or a particular kind of cluster is one of the tools that can be used to solve their problem, and if so, great! But there are likely other options they could be using, too. (Do you doubt me about finding researchers? Because I’ve been on several function-specific teams which were “the only game in town” at particular institutions, and we were constantly shocked at how many researchers had just never heard of us.)
The second is in having those researchers value your work. If you provide undifferentiated C++ programming or cluster administration, you’ll always do a worse job for that particular researcher than a team that did software development specifically for subsurface science, or a computing resource that can queue complex simulation-analysis-pipeline workloads. There will always be researchers who can take advantage of the undifferentiated offering, but they’ll be the ones who could just as easily move elsewhere the moment the opportunity arose. They won’t develop any particular relationship with the team nor advocate strongly for the team in particular.
The third is communicating your value to decision makers, funders, or potential staff members. “We write C++ research software”, “we run a big cluster” isn’t a compelling story. If you back it up with undifferentiated statistics - which is all you can really offer - even less so. “We completed 15 projects last year!”. So? Is that a lot? A little? How did that move a field forward? “We run at 91% utilization!”. Is that good? Bad? How did that help the University? You can try to beat the drum for case studies and high-impact publications resulting from the inputs. But it’s always going to be an uphill battle trying to get research groups to write them up or even bother notifying you about their paper. It’s hard because you’re running an undifferentiated resource, one they could replace if necessary. Writing something up for you is just one more low-priority item for the todo list.
Still, there’s a reason why this approach is common amongst teams to organize around - we’ll come back to it in a moment.
Because there’s an even worse way to “specialize”, and I see worrying trends of it happening as countries and regions rightly start taking research computing and data more seriously. And that’s by “pillars” (read silos) - software, data, and infrastructure.
This approach kind of made sense in the 90s or early 2000s. Systems were getting increasingly homogenous, software was all of a certain kind (3d physical simulations) that ran on those systems. Data teams if they existed at all were separate entirely, focussed on different users, in business schools or social sciences, and were all SAS/SPSS/whatever and SQL. There wasn’t much overlap.
Historically teams tended to be broken up that way, and that’s the genesis of most of today’s research computing teams in Universities. “Because we’ve always done it that way” caries a lot of weight in old institutions. And you see their legacy still.
Today, if you were starting from scratch, you’d never organize teams around those functions. It’s absurd. Everything in our field today is a combination of the three facets of research computing and data. The “data collection tools for health researchers”, for instance, is a combination of infrastructure (deployment of a backend), data management (handling sensitive data), and software development (the application itself). Bioinformatics is inherently software + data.
The increasingly unified, cross-function nature of such work is a challenge even for your faithful correspondent. Take a look at the articles in the data management section this week, for instance - CI/CD pipelines for data artifacts. Is that an infra thing, a software thing, or data management? How about cloud-friendly libraries for geospatial data? How about data analysis toolkits in the browser? Which section should those go in
For organizing a newsletter roundup it can still be helpful to bin articles by which facet is most distinctive, and mis-binning is mostly harmless.
If you’re deciding on how to fund efforts, however, the stakes are much higher! In that case, you really need to consider everything holistically, and binning into silos is a terrible idea. Data without software is useless, as is software that’s not deployed anywhere, as is a compute infrastructure with no storage. Even in the 90s, the best software teams were very aware of the systems their tools would run on and coded accordingly, and the systems teams were very aware of their workloads. Having the teams communicate across silo boundaries was something the best teams did. Both sides needed to know what was implementable. Organizing funding by silo right from the beginning makes that cross-silo communication much harder.
We as human beings need to organize somehow, though - we can’t communicate with everyone else in research computing and data equally. The highest impact teams I’ve seen (and, not coincidentally, the ones that are least worried about their funding in the coming years) are those that have a specific focus, usually disciplinary (mirroring the research community focus they support), and have cross-functional expertise in their team. They have enough knowledge to help a researcher see a problem through beginning to end. The researchers see them as partners, and will advocate for them. And that’s because they’ve organized themselves around what they’re supporting, particular kinds of projects, rather than internally focussed on a tool they use.
Does that line up with what you see on the ground? Are their other ways of specializing or organizing that you’ve seen work? Email me with that or with any other comments or questions by hitting reply or sending an email to jonathan@researchcomputingteams.org.
With that, on to the roundup!
The Uninspiring Manager - Matt Schellhas
Too much of what I imagined an excellent manager should be early in my career (not having really seen any) was focussed on personal characteristics. Such leaders should be engaging, people-persons… and inspiring.
It’s not that any of those things is bad, of course. Those are all traits and behaviours that can be put to good use as a manager or lead! But so can the default behaviours of quiet, attentive, carefully-thinks-before-speaking introverts. Or of keep-ticking-things-off-the-list achievers. Or of caring, emotionally intuitive, confidantes. Each has default behaviours that are extremely helpful in the right circumstance, and are downright liabilities in others.
Schellhas makes the case against needing to be inspiring to be a good manager. In his view, people mostly already want to do a good job, and what they need to accomplish that is: information; skill; and willpower.
Inspiration doesn’t help at all with the first two, and only temporarily for the third. A better use of energy than temporarily boosting willpower with some rah rah stuff, he says, would be to put effort into fixing willpower-sapping features of the job. Fixing flaky CI systems that make writing tests seem useless, or removing unnecessary reporting.
One thing Schellhas doesn’t call out that I’ll add - being able to communicate a clear vision for the team is, in my estimation, a requirement of the job. People need to know what they are aiming for, and how their work fits into that. And that vision might even be inspiring! But that inspiration best comes from the work and goals themselves, not from some charismatic leader.
Trunk and Branches Model for Scaling Infrastructure Organizations - Will Larson
Larson here is talking specifically about infrastructure teams. But this could apply to growing research computing and data teams.
The constraints are keeping the core operations of an initial team with a broad remit going while growing and adding capabilities. The model he recommends and has seen work is to grow slowly and, as particular well-defined areas start emerging as being important, to “bud off” a branch sub-team with that specialty while the “trunk” team continues on with reduced scope. In our context, this could be two officially different teams with different managers/leads, or, maybe less ideally, overlapping groups of competence within a single large team.
(By the way, this is all perfectly consistent with beginning with a team that already has a well-defined specialty - GIS data science or web/mobile apps for data collection or managing clusters for AI/ML workloads. The wonderful thing about research, and expertise in general, is that it’s fractal. No matter how small a chunk of the big picture you start with, as you zoom further in you see more and more complexity. You discover whole new parts of the map to explore and become knowledgeable in.)
The key things Larson emphasizes here is to be clear (internally and externally) about what who owns what responsibilities as a team branches off.
I really like this documented hiring process by 18F in the US Government. It’s a well thought out process, and it’s written in a way that you could send to candidates so they know exactly what to expect. It’s even in GitHub. I also really like their technical pre-work - it’s either to provide some code they’ve worked on, or to do one of four exercises. The exercises are simple but non-trivial get-and-process-data exercises that would give a lot more confidence about ability to do real programming tasks than some kind of fizz-buzz.
Minto Pyramid - Adam Amran, Untools
Amran gives a very clear formula here for emails that you also see in advice for briefing boards (or in our case, e.g., scientific advisory committee.). Start with a one-sentence paragraph of the conclusion (or the ask); then a listing of the key arguments; then the supporting details. I’d add that the subject line should reflect the conclusion/ask.
I’ve been thinking a lot about this recently. I’m generally ok about writing to-the-point, skimmable emails. But that skill may have atrophied a bit recently. In my previous job, I didn’t send a lot of emails (we used slack internally mostly). When I did send them, as a manager and as a big fish in a small pond, I… could kind of assume my emails would be carefully read. In retrospect I kind of got lazy and leaned on that, which I now feel sheepish about.
I’m in now an individual contributor in a very email-heavy organization. I can see very clearly the effects of getting lazy about sending bottom-line-up-front emails. I’ve tried to communicate some points via email to some very busy account managers in the past couple weeks, and some of the points just did not get across. So it’s time to up my game again.
Not every email lends itself to this formula, of course, but sticking to bottom-line-up-front is a good general principle.
Journal clubs, ranked from worst to best - Guillaume Filion
Journal clubs can be great. The usual failure mode is that few other than the presenter actually reads the paper in any depth, so there’s not much discussion afterwards.
Fillon ranks the journal club mechanisms he’s seen work the best.
Cancer R&D funding decimated during Covid crisis, says NCRI - Sophie Inge, Research Professional News
There has been and will continue to be a huge influx of research money into health, but the past few years have been really rough on cancer reseach. Not only is it no longer anyone’s #1 health research priority, a lot of the research funds comes from charitable giving which the pandemic-related recession hit hard.
NCRI reports a drop of 9% of funding, which doesn’t sound like much but the majority of funding spending is on salaries. No doubt infectious disease research rose at least as much in absolute numbers, but people with years of training and expertise can’t be repurposed as easily as dollars can.
In general I think the coming years are going to see increasing changes from the pre-2020 baseline research funding landscape.
AI did not cover itself in glory over the past two years of COVID, and neither I’d argue did HPC - while bread-and-butter high-throughput computing and on-the-desktop bioinformatics workflows were invaluable.
Building a technical conceptual map (or “conceptual diagram”) of a subject. This is a very useful technique for learning a subject, or for preparing for teach a subject. It’s sort of a typed mind map. It can be used for very specific topics such as here Javascript’s reduce() method, or for the topic of a semester long course. Either way it’s very helpful for organizing an initially amorphous mass of concepts and identifying the key things to cover and in what order.

Black hole “billiards” may explain strange aspects of 2019 black hole merger - Jennifer Ouellette
Oulette at Ars does a great job describing a recent nature paper where the authors (Samsing et al) ran a large ensemble of 3d post-newtonian particle simulations trying to understand a weird merger, GW190521, that VIRGO/LIGO detected in 2019. The merger implied a total of 150 solar masses of black holes involved, which is a weird number - most black holes are either a few to a couple dozen times solar, or much more massive. Even weirder, a month later there was a big flash in the area.
In the paper by Samsing et al., the ensemble of simulations showed that adding a third black hole increases the odds of eccentric orbits by two orders of magnitude (and accounts for the observed strongly misaligned spin axes). If the merger occurred in an environment with multiple black holes in a big disk - say circulating a supermassive black hole - that could account for all observations.
Relatedly, if you want cool black hole pictures, here’s a blog post (including a figure below) demonstrating increasingly realistic rendering of accretion disks around black holes with the Unity game engine.

Survey reveals 6000+ people develop and maintain vital research software for Australian research - Jo Savill, Australian Research Data Commons (ARDC)
Research Software Capability in Australia - Michelle Barker and Markus Buchhorn
Interesting results from a late-2021 ARDC survey on research software capability, of 70 managers of Australian research computing and data groups. Results were scaled to try to give an estimate of all-of-Australia numbers.
The article by Savill gives an overview, and the full report by Barker and Buchhorn is interesting reading. Some key findings taken from the article and the report:
These numbers - and the problems they suggest - seem plausible to me for Canada, as well. The reliance on unfunded and part-time software development and maintenance is a real issue, as is the lack of any kind of coherent career track (80 job titles!!). The good news is that 43% of respondents had plans to recruit more people into those roles over the next 1-3 years.
Do these proportions seem about right in your neck of the woods (be that geography or discipline?). Do things look like they’re getting better or worse?
Building a Backlog Your Team Will Love - Blurbs By Amy
At my last job — and this was my fault — the backlog became an undifferentiated mass. We did keep higher priorities to the top, and lower priority items to the bottom. There was a lot there, though, some we were clearly never going to get to, and the tickets were of very different size… yeah, it wasn’t great.
Here Amy outlines her teams workflow, and it looks pretty good:
I like the unambiguous process here. You’re clearly doing something wrong if you add a ticket anywhere than “add new here”, for instance. Having two different parking lot sections seems a bit much, but it lets you move tasks into “Future nice to haves” without feeling like you’re consigning it to the dustbin. Over time clean-up can move things into Not Planning to Do, and adjust the priorities of groomed tasks.
Congratulations to the Python core team for deprecating and then removing some old stdlib modules. Choosing to stop supporting something is genuinely hard, and at Python scales even clearly past-its-best-before-date modules like cgi (cgi!!!) are probably used by thousands of people. Getting rid of a stdlib (and thus de facto default) cryptography module which is woefully inadequate for today’s world will avoid many more headaches than getting rid of telnetlib et al (telnet!!!) will cause.
This is the most succinct explanation I’ve seen on how to start using smart pointers in C++, and when to use each.
Developing a modern data workflow for regularly updated data - Glenda M. Yenni et al, PLOS Biology
Updating Data Recipe - Ethan White, Albert Kim, and Glenda M. Yenni
This one’s a couple years old, and I’m surprised I hadn’t seen it before.
It’s getting easy to find good examples for scientists of getting started with GitHub, and then to CI/CD, for code. But for data it’s much harder. And there’s no reason why experimental data shouldn’t benefit from versioning, and analysis pipeline CI/CD that code does. As data gets cleaned up and the pipeline matures, and data products start being released, these tools are just as useful.
Here the authors publish a recipe, instructions, and template repos for Github Actions and Travis CI with data. The immediate audience is for ecology, but the process is pretty general. The instructions cover configuring the repo, connecting to Zenodo (for data artifacts) and the CI/CD tool. Then data checks can be added (with the pipeline failing if the data breaks a validity constraint). And data analysis can be done, with data products being published and versioned when a new release is created. It’s really cool!
By making the things we want to see (data checking, proper data releases) easier, as with automating them, we get more of what we want to see in the world. This is very useful work.
Jupyter Everywhere - Martin Renou, Jeremy Tuloup
We’ve talked about JupyterLite (#77, #112) before - a compiled-to-web-assembly JupterLite and Python engine that lets you run Jupyter entirely in the browser, with no aditional back end. Here Renou & Tuloup describes the latest version that has a REPL application that ships with default, so that the NumPy website lets you play with NumPy code interactively.
The authors walk you through several ways of “deploying” JupyterLite in static webpages, as a standalone static page in GitHub Pages or Vercel or Netlify, or including it in sphinx output for documentation, either as the repl or the entire notebook UI.
This is going to make teaching training sessions and giving demonstrations much easier, and make documentation much more interesting!
An Exploration of ‘Cloud-Native Vector’ - Chris Holmes
GeoParquet - Chris Holmes, Tom Augspurger, Joris Van den Bossche, Jésus Arroyo Torrens, Alberto Asuerro
I really like this and I don’t even do geospatial work.
In a lot of fields, file formats have grown in perceived importance well beyond any reasonable measure. (Hi, bioinformatics!) People spend a lot of time arguing how bytes should be arrayed on disk, rather than focussing what APIs the data libraries should support, pinning down the API, and then supporting one or more data layouts that support the APIs efficiently.
In geophysical data, NetCDF was a big help and nudged the community in productive directions. It laid out a pretty strict API for labelled gridded data, with a couple underlying file representations. Conventions (basically formats) developed around how to store different kinds of data in the NetCDF APIs, and that was that. File formats changed over time (including pretty drastically with NetCDF4), and it was all cool because there were tools to convert.
Parquet is becoming that lingua franca for columns of data, which is what you frequently want for reading data into memory or streaming through it to get relevant pieces. GeoParquet is a library (and proposed de facto standard) for storing GIS-type data in Parquet. One of the lovely things about Parquet is that it ties nicely into Arrow for computing on or interchanging the at a in memory.
In the article, Holmes lays out the advantages of Parquet format to some other attempts. He refers to Parquet (and some alternatives) as cloud-native, but efficient columnar data formats work just as well streaming through data on-prem, even on block storage. Parquet is built to support cloud-native things like streaming data, but that’s not necessary for this to be a useful format. The repository at the second link has v0.1 of the specification.
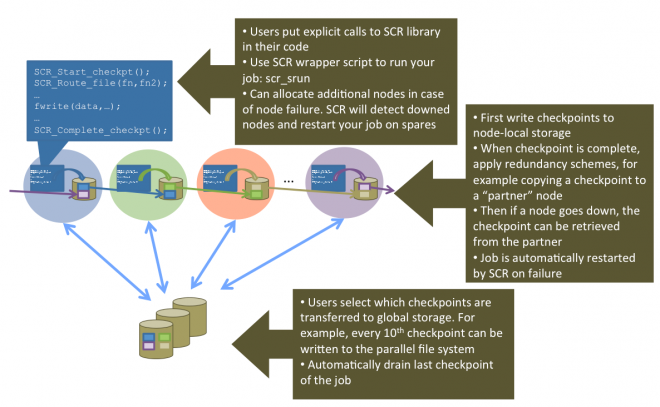
SCR: Scalable Checkpoint/Restart for MPI - LLNL
Coming back to HPC, I’ll probably be “discovering” things that have been going on for a while when I wasn’t paying attention - apologies in advance. This is the first I’ve heard of LLNL’s open source scalable checkpoint/restart library, which already had it’s v3.0 come out recently. It makes use of the increasingly hierarchical nature of storage, flushing checkpoints out to local storage, and then only periodically pushing one of the checkpoints out to global persistent storage.
cr8escape: New Vulnerability in CRI-O Container Engine Discovered by CrowdStrike (CVE-2022-0811) - John Walker & Manoj Ahuje, CloudStrike
Good overview by Walker & Ahuje of a vulnerability in the CRI-O container runtime, used by default in many new kubernetes installs, which lets users who can create pod definitions initiate pods which can be escaped from due to addition of support for (and insufficient validation of arguments to) sysctl.
Philosophically, I’m actually pleased to see that published exploits for escaping container runtimes are becoming increasingly either complicated or reliant on processes around operation; things are getting very mature. On a more practical nature, if you’re running CRI-O 1.19 and up, upgrade to patched versions, downgrade to 1.18, an/or add k8s policies to block pods that contain sysctl settings containing “+” or “=”.
Automating OpenStack database backups with Kayobe and GitHub Actions - StackHPC
In most of research computing, gitops isn’t advanced much past software deveclopment CI/CD pipelines (which are already great!). But we can do a lot more tying version control changes to configuration files to deployment. Here the StackHPC team walks through using GitHub Actions (or GitLab CI/CD) to automating open stack database changes using their tool for Kayobe automation.
Growth in FLOPs used to train ML models - Derek Jones
Compute Trends Across Three Eras of Machine Learning - Jaime Sevilla, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, Pablo Villalobos, arXiv:2202.05924
Jones has a nice summary of a paper by Sevilla et al., who went through the literature finding 493 ML models, and recording estimated flops for 129 of them, and very helpfully made their data available. Sevilla et al. looks at the data through the lens of pre-deep learning, the start of deep learning, and large-scale deep learning. Jones looks at it from the kinds of compute systems used: generic university clusters or other DIY systems, cloud computing, and more recently some special-purpose deep learning systems. It’s an interesting and fairly clear trifurcation:

Jones concludes with:
Supercomputer users have been facing the possibility of hitting the wall of maximum compute for over a decade. ML training is still a minnow in the supercomputer world, where calculations run for months, rather than a few days.
This overstates things in my opinion - recent peak usage of 1e24 FLOPs used to train a model is four months on a 100PF system assuming 100% efficiency - that’s a hero calculation by any measure. And usage is trending up very fast.
Some war stories from that weird liminal time when the internet was starting to genuinely be a thing but dial-up modems were still key pieces of infrastructure. (SLIP! PPP! T1 Lines! Alternet!)
Ever want to design your own chip and have it fabbed in the dozens or few hundreds? That’s actually possible now.
Why typography is so hard on web pages. Bring back metal type!
A very deep dive, from one of the key authors, of the whats and whys of significant improvement of random number generation in Linux 5.17 and 5.18.
Another very deep dive, from people trying to reverse engineer it, into the Apple Silicon secure boot process. Through their efforts, you can now run Linux on your M1 Mac - Asahi Linux.
A little tool for building simple interacting systems (like predator-prey) and adding complexity, maybe useful for explaining simulations to school children? Loopy.
Writing scripts in golang.
Compiler tool to use machine learning to provide “profiling” information statically to link-time optimization steps.
Log and audit all SSH commands by using Cloudflare (or something else) as an SSH proxy.
Some problems in programming languages are very, very old. C++’s cstring.h strings vs std::string? Elixir’s binaries, strings, and charlists, or Erlang’s Strings/Binaries/IO Lists/IO Data? Rust’s String vs &str? New-fangled copycats. Meet COBOL’s two string types.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
This week’s new-listing highlights are below; the full listing of 163 jobs is, as ever, available on the job board.