jonathan@researchcomputingteams.org
Before we get started, please answer if you can a question from a reader: What do you use to get and keep track requests for your work from researchers? Is there a ticket-tracker type piece of software that works for you, or do you use something else? Does it fit your workflow - What do you like, not like, and wish for?
I’ll summarize results next week - it’s an important topic!
One of the great things about this community is the different kinds of research computing and data teams I get to talk with, “here” or outside the inbox. Sometimes in these conversations it’s pretty clear that some teams, or the team and their funder, or a team and I, are talking a bit past each other. And that’s usually because they or we are (currently) operating with very different mental models.
Some research computing and data teams are operating as Utilities, and see the world through that lens; a growing number are operating as Professional Services Firms. Different groups are at different places along that very abrupt transition. Some kinds of groups (like bioinformatics cores) are much more likely to already be operating in service mode, while others (like research compute infrastructure teams) are more likely to still think of themselves as utilities. It varies from place to place, though, depending on local conditions. But they’re very different models!
Utilities, like power companies or garbage collection or municipal potable water, were really the only sensible role models for the first decades of research computing and data teams. Those teams were entirely about operating large equipment purchased from vendors. Costs were mostly a big capital expense. Everyone who needed the utility needed the same thing - undifferentiated flops and bytes, or 60Hz 120VAC. Because everyone needed the same thing, economies of scale led to natural monopolies; the most reasonable provision model was for the local jurisdiction/institution to own or control a single operator. Differentiation or strategy, or gaining new customers, weren’t meaningful discussion topics. Innovation happens slowly, top-down, at the industry-wide scale (“hey, did you hear about those new gas compressors Dyneco announced?”), and diffuses outwards. Employees take pride in and the organization values operational skill and things ticking along smoothly. Customers value reliability. The only thing that matters for any individual operator is to operate effectively and to provide the standard service with the right amount of cost: high enough to absorb the available subsidy, low enough to not go broke. If a customer needs something other than what the utility provides, rather than that being a market opportunity, it’s either an inconvenience or an irrelevance. The power company or the water utility or the old phone monopoly just doesn’t serve that need.
Professional Service Firms — say engineering firms, or architects, or consultancies — are very different beasts. They might very well have significant capital investment in specialized equipment, but their main selling point and their biggest cost is expertise. Competing for and retaining that expertise, and developing that expertise in house and amongst their clients, are principal concerns. As part of a “full-service” offering they they likely have some fairly standard services they offer at the low end, where operating cost and efficiency is vital. But what the organization values, and the employees enjoy, is at the high-touch end — getting deeply involved with the client work, and being as much a collaborator or partner or “trusted advisor” as a service provider. Different clients want very different things, and that high-touch high-expertise work is specialized and labour intensive, so the firms themselves need a clear focus; they can’t meet all needs. Clients can go elsewhere, so there is redundancy and competition, but less than you’d think at a distance. In civil engineering a geotechnical firm is complementary, not competing, with one that specializes in water resource engineering.
As in the rest of our lives, in research computing we need to have utilities. As research data management matures, institutional or regional data depositories become mature and “enterprise” enough to become utilities, likely run by IT or the Library. Teaching or CI/CD or MLOps resources for data science or software development are likely best served by this model.
But as research computing becomes broader and faster changing, we need more professional services firms, too; nimble groups specialized to particular needs and ready to adapt as those needs change. As even infrastructure is becoming less one-size-fits-all, and methods for making use of computing and data for diverse fields grow more complex and expertise intensive, the preconditions for the utility model are met in fewer situations than used to be.
A lot of research computing teams are interested in providing something more like professional services, but were created in the Utility model, and are stuck there by their funders. The institutional or external funders still have this very specific (and to their mind time tested and successful) operating model in their plans. And utilities are funded very differently than professional services firms. At utility scale, it doesn’t make sense to outsource things, or develop non-standard services (who wants non-standard power coming into their house!) Funders requirements on eligible expenses may focus almost entirely on the capital spend, and not on operating funding that’s needed to make effective use of the capital, or to be more agile in how services are delivered.
Even those teams who aren’t being held back by funders and who want to make the switch to professional services from their original utility model find it a hard transition. There’s no obvious, incremental path to go from providing a standard, stable commodity to changing, specialized, bundles of expertise. Their existing customers don’t want change, and new customers aren’t yet interested in getting appliance suggestions from what they perceive to still be the power company.
But research computing and data is changing, increasingly quickly, and the Utility approach only meets a piece of these growing needs. Navigating the transition isn’t going to be easy, for RCD teams, leaders, or funders; but expressing it clearly and talking about it more will maybe mean we’re not talking past each other so often.
With that, on to the roundup!
RCT Job Definition Worksheet v1: Letter, A4 - Research Computing Teams
I’m going back through past issues and trying to group the most useful resources by topic (jeez, folks, I write a lot of stuff in these.. is it too much?). A common topic, and a common problem people talk with me about, is hiring and onboarding. There’s two common threads I see:
First: one huge difference between our work and that of (say) IT or large tech firms is that figuring out what the job is even supposed to be takes some doing. Our teams aren’t large or static enough to have pre-existing cookie cutter roles requiring previously documented skill sets. (Startups are more like us this way.) The work is fluid. Each hire, each job, is a bit of a one-off, a bit bespoke.
Second: Hiring and onboarding (and, for that matter, early evaluation of performance) are the same process. Once we’ve had an offer letter accepted, we don’t dust off our hands and declare our work done. The reason we hire someone is to have that person become successful at some work that needs doing. We need to bring them up to speed, and (for both their sake and ours) to have a clear progression of goals for them during that process. The best time to figure out what that would look like is during the process of defining the job, in parallel with writing up the job ad and the interview evaluation process.
So I’ve distilled what I could from resources that have shown up here, combined with things I’ve used in the past, into a worksheet. The goal is to have something the hiring team can hash out together. This is version one - feedback welcomed! (Feedback is a gift). The section headings aren’t rocket science, but the order matters:
Iteratively hashing this out with the team will help develop consensus about what the job is and how to interview. And at the end you’ll be have the beginning of an onboarding plan. You’ll also be able to include clear 30/60/120 day goals in the job ad. Good candidates appreciate those goals: those alone offer more clarity about the job than most entire job ads do.
Ten simple rules for improving communication among scientists - Bautista et al., PLOS Comp. Bio.
This paper is intended for scientists - especially but not solely juniors - to get more connected and integrated with a scientific community. They outline seem particular approaches, and (importantly) the idea that there should be some clear goal or goals in mind when applying them.
The same approach and methods are useful for teams operating in a more “professional services” styles, where connecting to your current and potential clients and learning their needs, as well as making yourself known, is vital. Power companies or the old phone monopolies don’t need to learn about their customers.
The suggested approaches re:
Women are Credited Less in Science than are Men - Ross, Glennon, Murciano-Goroff et al, Nature
Who gets credit for science? Often, it’s not women - John Timmer, Ars Technica
Timmer’s article in Ars Technica is a good summary of and pointed me to the Nature article, which looked at data covering nearly 10,000 individual research teams and over 125,000 people, cross-linked to databases of publications and patents. The results are pretty grim - women are systematically less often ever made authors than men. Maybe worse, the disparity is worst for more junior people (including research staff, like many of us, where the disparity is close to a factor of two), all but ensuring that women find it harder to become more senior with fewer authorships on their CVs.
Lots of good shell tutorials out there for researchers or new-to-the-terminal staff, but most of them cover the same things in the same order. Effective Shell is one I haven’t seen before, and the order is quite different: it covers working with the clipboard right away (pretty handy for a shell tutorial so people can copy-and-paste lines - right?), then simple pipelines, then command line short cuts, so people can start to feel efficient and fast, and only then the rest of the usual stuff. Really interesting.
Here’s a case study of very successful software project that’s both a teaching and learning tool for introductory software development (originally just in Python but now also in Java, C/C++, JavaScript, and Ruby) and used in researching how computer programming is learned and taught most effectively.
Guo credits Python Tutor’s success - both in number of users and longevity - to staying extremely simple and focussed, insisting on a clear vision of building a single useful thing. He added capabilities only where it was clearly worth the development effort and was aligned with that vision; ignoring most user’s feature requests is one of his ten recommendations (listed below). This singularity of focussed was both made necessary and possible by the fact that he is the only developer of this tool, and it was a side project when he wrote it in grad school. Besides the number of users, it has been used as a key part in 55 papers that he knows of.

You don’t need a Platform, you need One Thing That Works: All carts, no horses - Paul Craig
Enterprise architecture is dead - Sean Boots
Companies Using RFCs or Design Docs and Examples of These - Gergeley Orosz
The first two articles came out this week from the Canadian Public Sector blogosphere. While they are aimed particularly at govtech, they’re also relevant cautionary tales for large efforts in the broader public sector, including many of us.
There’s a huge tendency for technologists who have been around a while, when put in charge of a large effort, to start from the big picture down. That’s true of a national effort or of a large single project. This tendency is a version of the the second-system effect. If we’re asked to build something that will eventually be big, the final state of a successful effort is likely a platform. So there needs to be standards! And well-defined interfaces! And a coherent overall architecture! Those will be necessary to accelerate the platform’s success!
Those are good things, but that’s the wrong order. Having any success at all is very much not a given. Standards and interfaces shouldn’t come first. There are many, many, many stories of large efforts that started with coherent overall visions failing to ever materialize at all. Way more than the number of stories of successful small working things made by one organization failing be work together somehow over time. Yes, after-the-fact refactoring and integration may be a lot of not very fun work. But when the small things are things we built, things we have under our control? That’s work we know how to do. It’s work that we only know is worth doing when the small things are already useful.
Both articles are excellent. They’re hard to summarize, except Craig’s article has some pithy categories for failed platforms:
and for how to avoid them
(I’ll just add that we hear about these failures in government because of transparency laws. These failed platform or “enterprise architecture” efforts happen all the time in the private sector. In the government, it happens under media spotlights. But the private sector has the luxury of being able to wait until nightfall, roll the failed effort up in a carpet, and sneak it out the back door to a nearby swamp for disposal. Failed academic initiatives sadly usually get the same discreet treatment, making it hard to learn from past mistakes.)
The third article points out that while a lot of large tech companies do in fact have very sophsiticated and coherent architectures, they’re often bottom-up or at least collaborative efforts rather than being imposed top down. Orosz has a list of > 100 companies that he knows of that use some sort of request-for-comments process for architecture, with examples from companies like Google, HashiCorp, and others.
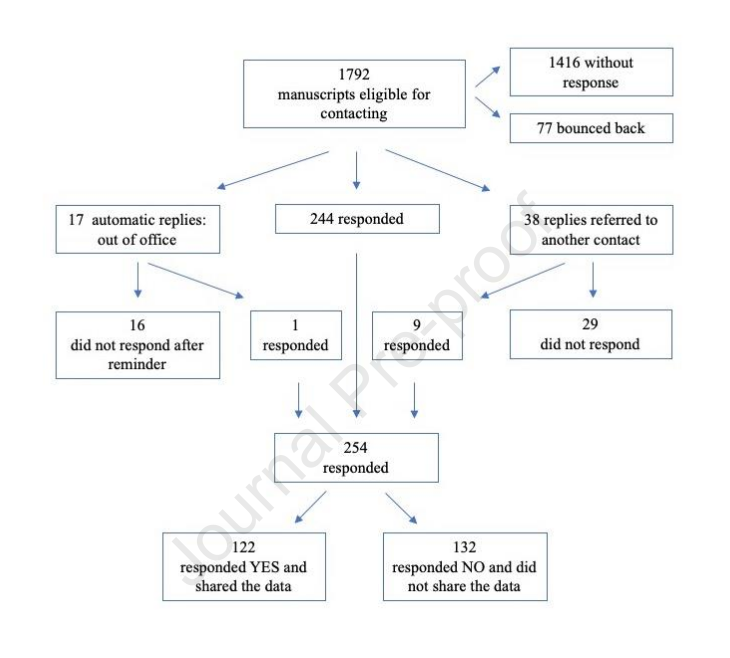
Many researchers were not compliant with their published data sharing statement: mixed-methods study - Mirko Gabelica, Ružica Bojčić, Livia Puljak, J. Clinical. Epidemilogy
A sobering reminder that we just can’t rely on individual researchers if we want a research ecosystem where data is shared and reused. We demonstrably need FAIR data repositories.
Authors from 1,792 manuscripts where its was stated that data was available upon request, only 7% actually responded and shared the data. 1,432 didn’t even bother responding. The reasons given from the 132 that did respond and said no were either clearly inadequate, or were reasons that would have been known at time of publication so they had no business having said that data would be available by request in the the first place. Michael Hoffman has a good tl;dr summary on twitter.
Open source data-diff - Gleb Mezhanskiy, Datafold
Another use case for pushing operations to the database for efficiency (and to avoid writing code). Data fold’s open source tool data-diff will diff columns between databases (even comparing, e.g., a column of Postgres to a column of MySQL or Snowflake or BigQuery). In the usual case where the data is mostly the same and you’re looking for a small number of different rows, it is is vastly faster than pulling the data out of the database to compare. It divides the dataset into chunks, and hashes an aggregate of the chunk, then doing an n-ary search to find mismatch rows if the chunks differ. Great for e.g., finding issues with automated data replication, or testing to see if a local copy of a dataset has any out-of-date records. Very cool!
Effective Cybersecurity for Research - William Drake, Anurag Shankar, Centre for Cybersecurity Research, Indiana University
The EDUCAUSE Library has a very nice and clear case study written up by Drake & Shankar about their work at Indiana University. They describe the work putting together SecureMyResearch, as part of a larger effort to offer a coherent approach to securing research computing and data at the University. (I’m very impressed by the clarity of the SecureMyResearch landing page. It makes it clear who it’s for, what they offer, questions they can help with, and how they can help). They developed ten principles for their work - starting with focus and success, with the other eight all about people and process, not particular technologies.
The whole effort required only two net new staff, along with a clear person in charge, accountability, and institutional support (the last, admittedly, a mandate issued last year by the US government helped with). Leadership and staff had to coordinate across a number of departments and functions to get the work done. And of course communicating with the wide range of researchers took effort. I’ll highlight one point too often missed:
The lesson taught us to ask, “What is it that you are trying to achieve?” instead of bragging, “Look what great toys we have for you.”
There’s now an organization under the Linux Foundation, joined by most of the big players, to help standardize the programability of SmartNICs/DPUs/IPUs. That’s terrific news and will speed adoption while making sure research computing teams don’t have to worry about lock-in. One of their first tasks listed is to “Define DPU and IPU” which by itself would be welcome.
Competition in the AI code completion space. Along with the news that GitHub Copilot (which I continue to enjoy) has gone GA and will charge $10/mo, here comes another - Amazon CodeWhisperer, baked into AWS’s IDE products. It’s clearly learned from some negative press about copilot. CodeWhisper will check to see if the code generated is a direct copy of code in its training set, and show the licence of that code if it is. It will also do an an automated security check of the code generated.
(PS - the same internet-lawyer legal discussions about Copilot have popped up now as when it was first announced. Open source advocates, and especially those of us in research, should be very careful what we wish for. Asking copyright law to be so strong that data mining on large datasets is automatically a copyright violation has knock-on consequences. Do we really want Elsevier and Springer to be solely in charge of data mining the medical literature? Exactly how hard do we want the legal battle against sci-hub to be? It’s easy to say “that’s different” on the internet, but finding or enshrining those distinctions in the law may not be so simple.)
Debugging warstory of a weird bash pipe problem.
What Canva learned from putting a half-million files in one git repository. It seems like it would have been easier to just not do that?
Dangit, Git!?! - a cheat sheet of un-fubaring yourself from common git mistakes.
If you’re going to stick with Copilot, here’s how you can use it in Vim, using a container.
There are more search engines out there than I realized - an overview of search engines with their own indices.
This is interesting - Tailscale now has its own ssh support, using tailscale authn without keys.
Fortran’s community-driven stdlib now has hashmaps. This is very much not the Fortran I grew up with.
I’ve mentioned some cool SQL-against-data-in-its-native-format tools in the newsletter, but of course you can query CSVs with sqlite and duckdb directly (and if you’re going to be doing analytics on the CSV, you really want duckdb - analytics is its job).
Fuzzy searching (and bookmarking) your shell history using fzf.
Old, but I hadn’t seen it before. An entire working computer - RAM, ROM, an ALU, and a simple assembly language - to play Tetris, implemented entirely in Conway’s Game Of Life.
Running Doom on an Ikea smart lamp.
Interesting bounty program for submitting PRs to address issues with urllib3 - much finer-grained funding than, e.g., hiring a dev.
A collection of text-format-visualization tools, including for JSON, regex, YAML, SQL, Git, Docker container ops, and Kubernetes.
How CVSS vulnerability severity scores work.
PXE boot from various operating system installers using a single tool over the network - netboot.xyz.
Fixing issues with docker builds of python apps on Apple silicon (and, I assume, other Arm platforms).
Distributed postgres with the now open-source Postgres Citus plugin.
A run-time type checker for bash.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.