jonathan@researchcomputingteams.org
I feel strongly about the RCT job board — operationally, one of the things that defines a profession is some common places to look for new career opportunities. It indicates that there is widespread recognition of and demand for the skills and expertise of the community. It demonstrates that the community has grown and diversified enough to offer a variety of career paths and options for its members, and that the community supports their professional development and mobility. It’s important for the specialized and important community of practice we’re trying to build here together, so please keep submitting those jobs!
But another terrific use of the job board is just as a source of data, tracking the needs of the institutions who require our services. In maintaining the job board over the last three-ish years, I’ve already seen some changes. And going through the postings recently, there are some pretty clear shifts.
Some won’t be that surprising to… well, to anyone. There are a tonne of quantum computing lead or manger jobs, something that barely even registered as an option three years ago. There are a lot of jobs for very applied AI teams, whereas when I started they were dominated by exploratory research groups. (And when I started this, “machine learning” was declining as a term used, in favour of “data science”; “machine learning” has already caught back up.) The demand for bioinformatics manager roles, which skyrocketed during the early stages of the pandemic, has somehow stayed steady.
Academic job postings are still staying up forever before getting filled, but I notice amongst those jobs a richer and more challenging set of roles - increasingly, campus-wide jobs, often with multiple of our disciplines (software, data management, data science, computing platforms), and explicitly designed to interact with other teams within the same institution.
This last change is related to the biggest shift I’m seeing. RCD teams have truly arrived - it’s no longer about exploratory work for a few already sophisticated users. It’s a fundamental and necessary part of all forms of research.
And that’s being recognized and in increasingly operational, professionalized, “keep the ship on course” sort of roles, titles and job descriptions I rarely if ever saw even 18 months ago:
Our institutional needs are changing. (Well, they had already changed. Now the institutional decision makers have recognized that the needs have changed.) There’s growing understanding that to have the greatest impact on science and scholarship possible, “best effort” ad hoc approaches aren’t enough. Teams aligned with other teams and with institutions on priorities, executing regularly and reliably while growing and developing new capabilities, are what’s needed.
People like you, reading this newsletter, are by definition already the ones trying to find resources and use them to improve how your team supports research. We’re preferentially the ones thinking about processes, using retrospectives to build our teams and improve our work, making sure we’re meeting actual researcher needs by actually talking to them, sharing knowledge internally, working with not competing against other teams, defining clear services, and holding and enforcing clear standards - all in the service of making science and scholarship better.
It’s the other teams I worry a bit about.
The gap is already pretty clearly visible between the teams that used the turmoil of the last few years as a spur to become more intentional about how they worked together, more capable, more supportive of each other, more flexible and quicker-reacting, and those that just kind of muddled along. As the expectations grow from our institutions, I suspect that gap will grow.
I want those other teams to do well as standards rise — the team members, and the researchers at their institutions both deserve that — but I’m honestly I’m not sure how best to make sure they get the support and encouragement they need.
Do you have any suggestions? What made you first start looking around for resources to help support your team better, and what did you start looking for? What are some resources that such managers need for them to get started on that journey? I’d love to hear any suggestions - please just reply, or email me at jonathan@researchcomputingteams.org.
In Manager, Ph.D. earlier this week, I talked about:
Project Management for Software Engineers - Kevin Sookocheff
Sookocheff writes a good crash course into project management for those in computing fields - most importantly because it doesn’t fall into the usual trap of going straight to some tool or process.
Project management, the empirical art of successfully finishing things together, is a response to decades (centuries? millennia?) of projects failing in the same ways. It can be written out quite grandly, but it comes down to just four things, in order of importance to us in our line of work:
Planning and foresight are vitally important, of course, but in our teams that’s usually pretty well under control.
If you couple that with communications (both ongoing and of a clear, mutually understood goal), accountability for staying on track, and adaptability as things come up, the project is more likely to succeed than fail. Without them, the default outcome isn’t success.
Sookocheff does a really nice job of walking through key parts of the project process from PMBOK. He spends about half the time on project initiation, which is fantastic - if a project takes shortcuts here it can lead to mistakes that just can’t be recovered from. Then he emphasizes communications and accountability through the rest. It’s definitely a good resource to keep handy for the next time you delegate a team member their first project management responsibility.
LLMs will fundamentally change software engineering - Manuel Odendahl
GitHub Copilot X: The AI-powered developer experience - Thomas Dohmke
This is going to be an important topic for a long time - how do we use LLMs effectively in our work. Software development was a very early adopter on this, with GitHub Copilot, but now with free options like ChatGPT, Bing Chat, and Bard, on top of dozens of products popping up, it is going to only accelerate.
Odendahl’s article is a pretty positive take on the utility of the tools; I won’t be making any effort to balance it out with a negative take. As you know, in our line of work “we should keep doing things the way we’ve always done them” is pretty much the default, and we hear it enough from our colleagues. People like us who are actively seeking out better ways to lead and manage our teams don’t need to hear more of it, and most of the negative takes on the technology’s utility haven’t yet amounted to much more than that. There are real ethical concerns with the data going into the models and with LLMs wider impacts; I’m not qualified to curate readings on those topics. My beat, where I’ll continue focussing, is “how do we use these things that exist to advance research and scholarship in our institutions given our priorities and constraints.”
I quite like Odendahl’s article, because it has what I think is the right starting point:
We don’t know how to work with these tools yet: we just discovered alien tractor technology. Many critics try to use it as if it was a plain old gardening rake, dismissing it because it plowed through their flowerbed.
and yet suggests some of the ways LLM tools probably will change the day to day of programming:
It’s interesting to me that some of the negative responses to this article describe in detail their failed experiments having not made such changes to their workflow. To my mind that supports Odendahl’s main line of argument — to make the most of these tools, our workflow would have to change.
(Steve Yegge in one of his trademark rants this week mentions one of the most frequently heard concerns, that code coming from these tools may not be trustworthy: “software engineering exists as a discipline because you cannot EVER under any circumstances TRUST CODE.”)
Meanwhile, GitHub Copilot is announcing further technology previews based on GPT-4 (the main Copilot model is significantly earlier, and built solely on source code):
Are playing with LLM-powered tools something your software team is doing? What have you found works well, and what hasn’t? I’d love to know, and to share it with our RCT community if you’re willing - just email me at jonathan@researchcomputingteams.org.
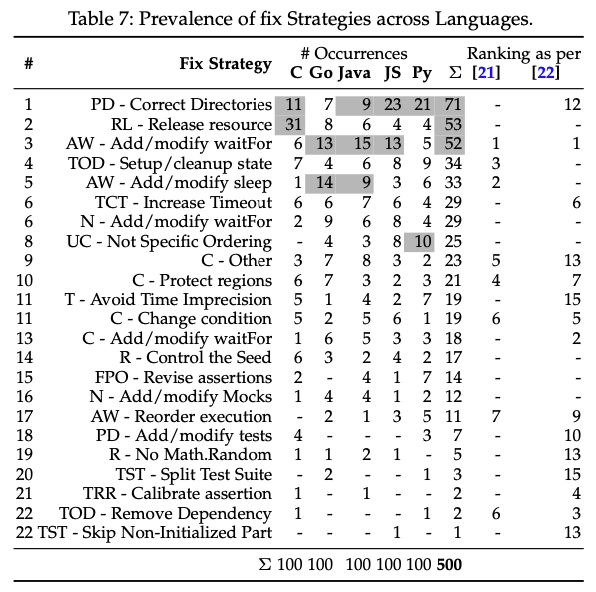
Test flakiness across programming languages - Costa et al, IEEE Transactions on Software Engineering
Test Flakiness Across Programming Languages - Greg Wilson, It Will Never Work In Theory
Interesting overview highlighted by Wilson on how causes of test flakiness vary by language of code base (resource leak being most common in C, dependency issues being most common in JavaScript and Python) but also how just a dozen strategies account for 85% of fixes.
Incentives to invest in identifiers: A cost-benefit analysis of persistent identifiers in Australian research systems - Josh Brown, Phill Jones, Alice Meadows, Fiona Murphy, MoreBrains
Persistent data identifiers aren’t glamorous, are fiendishly tricky to get to work correctly in all the various corner cases, and yet are absolutely foundational to data reuse.
This report was commissioned by the Australian Research Data Commons, who has released a number of great reports lately; this is part of their National Persistent Identifiers strategy and roadmap planning.
Here the authors go through three case studies of the use of persistent identifiers. The first is of the research process itself - e.g. ORCiD for connecting authors and papers, researchers and grants, etc. As the research endeavour grows (there are apparently 108,873 FTE academic staff in Australia), being able to effectively communicate research outputs of individuals and institutions grows more challenging, and requires some sort of automation.
Or not - the alternative is everyone doing it themselves manually, which the report estimates would chew up $24M worth of people’s time and associated costs.
What’s interesting to me is that even in this case where there’s a clear benefit to the people creating the IDs and using the metadata, and support in within the ecosystem for taking advantage of the persistent IDs, there’s still ongoing support needed to finish the adoption challenge.
Other case studies include PIDs for various use cases in Australia’s Terrestrial Ecosystem Research Network, and use of PIDs for other areas in the research ecosystem.
At a very different level of granularity, a call to use more modern SQL capabilities like window functions, PIVOT, MERGE, and INSTEAD OF triggers - Time to break free from the SQL-92 mindset.
Managing Risk as an SRE - Ross Brodbeck
Broadbeck describes the basics of the “SRE” approach to risk management - something that was called out by a whole chapter of Google’s book which popularized the practice of SRE for reliable uptime.
My experience has been that systems team members that have come from an experimental or observational science background have a stronger intuition for risk managment than those of us who come from a theoretical or purely computational upbringing. Even so, there’s often not a principled approach to risk management, thinking critically about and prioritizing risks, and having a real, nonzero risk budget (first rule of risk management: the ideal amount of risk is never zero, even if such a thing were possible, which it isn’t).
Our systems’ needs are different than those of a massive web services company - but that just means our risk prioritizations would be different. The approaches can still work very nicely; Broadbeck’s short article is a good starting point.
This has been in the news for a while, so you may well have already seen this (and certainly if you’re UK-based), but the UK Future of Compute report and recommendations is a commendably clear document that is expected to greatly inform the UK government’s thinking and so is worth reading for that reason alone.
The arguments made here will be familiar, so I won’t summarize it, but three things I kept coming back to while reading it myself:
Deep(er) dive into container labels and annotations - Christian Kniep
Kneip proposes using labels in container images, and their use in annotations and manifests, as a way to communicate execution-time metadata in HPC container systems.
Speaking of containers, I just noticed that there’s a Manning Podman in Action ebook available for free from RedHat if you’ve registered with a free RedHat account - I’m hopeful that Podman will have most of what systems teams need from container systems while not being quite as limited as singularity. Kneip’s post above mentions one advantage of podman, being able to use zstd-compressed images.
Early CPUs often didn’t have explicit hardware for multiplication, much less division - reverse engineering the multiplication algorithm in the 8086 processor.
This rise, fall, and influence of Visual Basic.
A cool online textbook on algorithms for decision making under uncertainty.
I can’t help it, I really enjoy various markup-based typesetting systems - some of my first non-handwritten assignments were written in troff, then latex, then markdown + pandoc. This new one, typst, strikes me as interesting.
“Miller is a command-line tool for querying, shaping, and reformatting data files in various formats including CSV, TSV, JSON, and JSON Lines.”
Implementing a transformer from scratch.
Notes on FFTs for implementers.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.
This week’s new-listing highlights are below in the email edition; the full listing of 185 jobs is, as ever, available on the job board.