jonathan@researchcomputingteams.org
Hi!
Last week we talked about ways to say no to incoming requests; besides a flat-out no, I mentioned the possibility of involving another team, or supporting the research group in doing the work themselves. RCT community member Adam DeConinck sent in another suggestion:
Occasionally, I’ve seen requests come in for work that the research computing team isn’t going to do; but which is also not something that another provider exists to do, and which the customer can’t do themselves even with training. When that happens, the “support” I’ve been able to offer is to join the customer in advocating for change. For example, aggregate similar requests and find commonalities; then organize the customers involved and advocate to upper management that they provide resources for this work to be done. That’s often not terribly satisfying, and I’ll admit that my success rate in doing this isn’t very high. (Non-zero, though!) But it’s often the only way I’ve found to create new classes of service within an existing organization.
This is a great suggestion, taking the long term view - and by lending your voice to the research groups’ in advocating for support for different kinds of work, it turns the situation into “your team and the research group vs the problem” rather than “your team disagreeing with the research group”.
This is the time of year when I’m just beginning to see the “out of office” emails in response to the newsletter - I expect them to grow more numerous in the coming month. Probably because of that, one question I got asked recently (and went up on the topics poll, receiving an upvote) was how to handle going on vacation.
Preparing to go on vacation is a great opportunity to practice delegation — to give your team members opportunities to grow in responsibility. That growth in responsibility can be temporary, but it can also be the beginning of a permanent handoff of some activities or responsibilities. One link I sent out back in #79, Always Be Quitting, described this mindset quite well and has been commented on several times by community members:
The key lies in NOT being indispensable. […] Paradoxically, by being disposable, you free yourself. You make it easier for yourself to grow into a higher-level role and you make it easier for yourself to change the projects you work on.
By bringing others into meetings you take, by documenting your knowledge and the state of projects, you make it easier for yourself to step back from some responsibilities to make room for other work, while enabling others to take them on. Vacation is a fantastic opportunity to trial-run delegation, to give you and a team member the opportunity to test the delegation in a very time-boxed way that’s readily explainable to others.
One-on-ones are are a great vehicle for finding out what professional growth team members are interested in - the RCT one-on-one template cover sheet has a spot for “what’s next” to keep track of possible next steps on their growth, and the quarterly goal setting and review forms include regular check-ins on career goals and a opportunity to start making explicit plans. Key to doing this well is the idea of a responsibility ladder (#12), or of task-relevant maturity (#50). Giving people growth opportunities while setting them up to succeed means not just dropping them in the deep end, but by giving them responsibility for gradually increasing scope in that area. This article on an engineering team where everyone is a leader, also from #12, describes the process in the context of software development projects in particular, but applies more widely.
When we have a good sense of who are willing and might be soon be ready to take on particular aspects of our current work, those are now target areas in which to tidy up our own work. We can make sure our documentation of the state of the effort is current, or start writing up the processes we go through, or collect meeting notes. Those can then be shared, and we can start bringing the team members to relevant meetings. We can review the state of those activities in one-on-ones, in preparation for any handoff. They could practice taking a meeting for us in that area, updating the one notes, and debriefing afterwards if some conflict arises (or can be arranged to arise).
If this has already been done before going off on vacation, great! People should be prepared and confident to step in for you on those activities over the coming weeks. But if not, in areas where there’s unlikely to be huge fires to be put out or decisions to be made in the short term, don’t let that stop you from handing off tasks in your absence. Do them and you the favour of being explicit about what they should and shouldn’t feel empowered to do on their own in that area, and what should wait for your return - but try to make that last as little as possible.
This article from #85, managers need vacations too, gives a nice overall checklist when getting ready to be away:
You don’t necessarily have to start doing all of this all at once your next vacation (or conference trip, or…), but these steps, combined with some preparation for delegating particular responsibilities, are a great place to aim to be after the next few absences. Debriefing afterwards will give both you and your team members an opportunity to discuss whether you’d both be comfortable taking on the responsibility permanently, with you still there to coach and advise,
Does that seem helpful? What other approaches have you taken to handing off responsibilities while you’re away? Let me know - just hit reply or email me at jonathan@researchcomputingteams.org.
Speaking of vacation, I’m going to take the next two weeks off from the newsletter - I’ll be back on Aug 19th or 20th (I’m going to try to get back onto a Friday schedule, although we’ll see how that goes).
With that, on to the roundup!
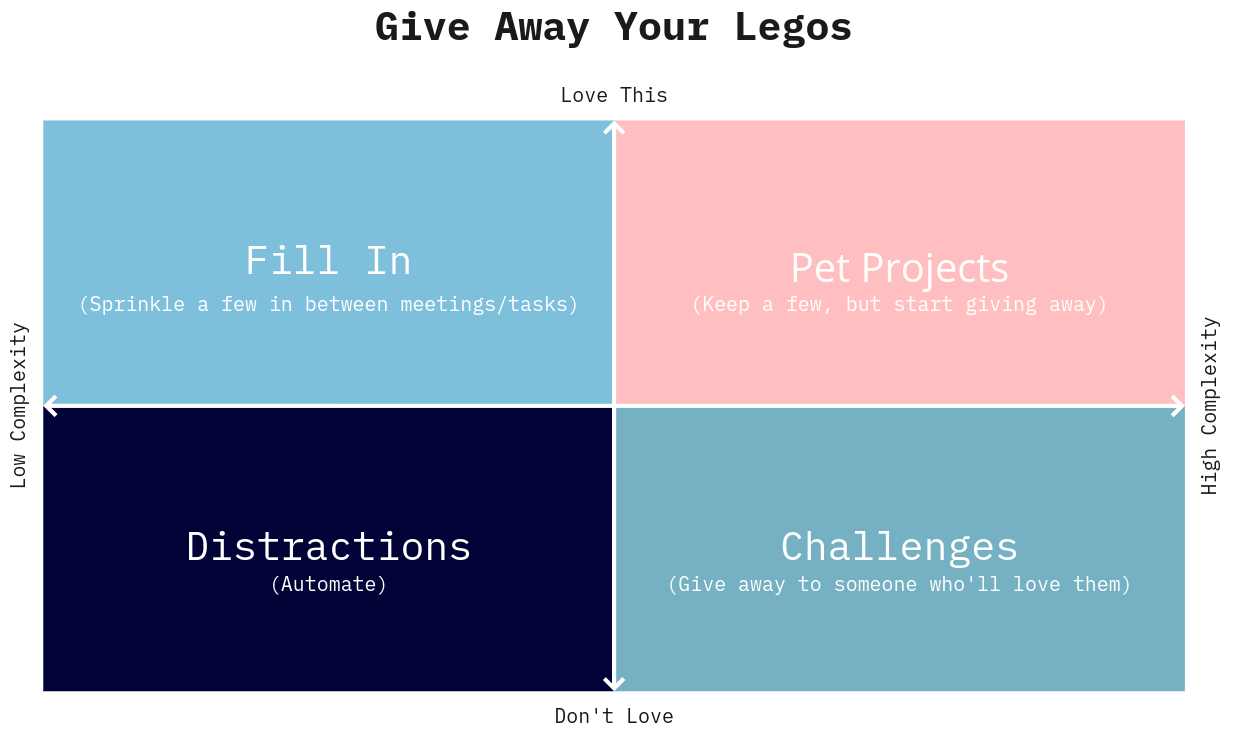
Give Away Your Legos Matrix - Evan Rutledge Borden
Very relevant to the discussion above - even after you get back from vacation, what tasks should you not take back on? Borden writes this article inspired by Give Away Your Legos by Molly Graham. (Graham’s article article was also recently recommended by RCT community member Rodrigo Ortega Polo, after the Bioinfo-core session he co-organized). The article is almost entirely the diagram below.
There’s only two things I’d add. The first is that over time, the bar for things you keep doing because you enjoy them should get raised higher and higher. It’s not bad, necessarily, to still hoard a couple of activities to yourself that you love. Yes, these are activities your team members will likely need to grow into eventually (such as when you’re away!). But maybe they’re the tasks that give you sine needed energy and engagement. The key is not to do it unthinkingly, but to realize what you’re doing and why.
The second is something RCT community member Scott Delinger has reminded me of a couple of times. Any even cursory audit of tasks such as this one should include a filter for “does anyone really need to keep doing this?” Love it or not, complex or not, if the team just dropped this task entirely how bad would it be, really? If no one did it while you were away, and you just didn’t start doing it again, is that something you could get away with? Do the benefits really outweigh the costs of your most precious resource, time? Usually the answer will be that you have to keep doing it, but when you do find stuff to stop doing that’s found extra time.
Note that in the diagram below, “automate” could literally mean just have a computer do the work, but it can also be work simplification by folding some task into some other regularly occurring process.
How to Deliver Bad News - Ed Batista
Whether it’s discussions with stakeholders, institutional decision makers, job candidates, or team members, we often have to be the bearer of bad news. It doesn’t get easy, exactly, but when we’re new to it we often make it even harder on ourselves than it has to be. That’s the part we can do something about.
Batista writes specifically about delivering bad news to more senior decision makers or stakeholders. Our part of these conversations is pretty simple (not easy, but simple) - he has a three-part formula:
We have to deliver bad news in a timely manner, but we should at least be prepared to talk about what we know about why something happened and have an initial recommendation for next steps.
Batista then describes three things that make things go a little easier - all of which are things we can influence:
Reviving an R&D pipeline: a step change in the Phase II success rate - Wu et al, Drug Discovery Today (2021) 26:308
I’ve talked before about the importance of specialization for being effective as a team, while not siloing (#114) - of focussing our efforts on particular kinds of problems someone external would recognize, while not necessarily limiting ourselves to particular set of technologies or approaches or tools that we use internally on those problems.
This isn’t an approach that we’re forced into because we only have small teams; it’s a more general approach than that. Here a group at Pfizer, a 79,000 employee pharmaceutical behemoth, describes how they improved their Phase II success rate from 19% to 53% (2.8x!). They did this sharpening their focus onto a smaller number of therapeutic areas, so they understood the problem domain better, while simultaneously increasing the number of approaches and technologies they brought to bear on that smaller number of problems.
In HBR there’s an article by Liz Fosslein on How to Pace Yourself at Work While Pregnant. It’s also useful for suggestions those of us like me who don’t know first or even second hand the challenges of pregnancy how to support our coworkers and team members who are pregnant.
How to Resolve These Five Problems of Struggling Software Engineers - George Marklow
Sometimes new and junior team members have individualized needs that some coaching and resources can help with. Other times, if new team members keep having similar problems, there may be knowledge-sharing or infrastructure problems in the team that can be resolved. Marklow covers both sets here:
A sobering reminder that our research community colleagues don’t receive equitable treatment Decades of systemic racial disparities in funding rates at the National Science Foundation by Chen et al. The results are even worse than the headline granting rate numbers suggest - many Black colleagues’ NSF research grants, for instance, aren’t for research but for education or outreach.
Mapping the future of Research Management - European Association of Research Managers and Administrators (EARMA)
Research management roadmap project ‘ready to launch’ - Craig Nicholson, Research Professional News
It’s nice to see that slowly, there’s growing recognition of the need for a professional cadre of research staff. It’s happening particularly slowly in the people or project/product management areas, but it is happening:
Europe’s leading organisations that represent research managers have welcomed the award of €1.5m from the Horizon Europe programme, to fund an unprecedented co-creation process that aims to define the future of the profession. […] The role of research management has undergone dramatic changes, in response to the ever-changing demands of the social and political context of public-funded research. Research managers are now an integral and vital part of the research ecosystem, and take many forms, including policy advisers, project managers, financial support, data stewards, business developers and knowledge brokers.
On the accuracy and performance of the lattice Boltzmann method with 64-bit, 32-bit and novel 16-bit number formats - Lehmann et al
It’s been clear for a long time that memory bandwidth is more of a limitation than raw compute for most scientific codes, but I think for a long time people have been hoping that some kind of hardware advances would make that pendulum swing back. Unfortunately, it doesn’t look likely. So the options are improving latency hiding one way or another and/or reducing memory bandwidth requirements by using smaller data types.
We’re starting to see some of the lower-precision floating point codes now. Here’s a nice example of lattice Boltzmann in particular doing very well at lower precisions, with some care put into the algorithm to not unduly require range and precision by, for instance, normalizing density functions. The authors here distinguish between the storage precision and the precision in which the results are calculated - e.g. FP64/FP32 means that the data is stored in memory in FP32 at each time step, but intermediate calculations are done in FP64.
Here the results from FP32 and FP64 are indistinguishable, and with the “right” FP16 precision, noise is well controlled. Here among other formats they play with posits, a non-IEE754 approach, for storage; there’s no hardware support for these, but the savings in memory bandwidth almost balance out the need for software conversion to FP32.

ML-Enhanced Code Completion Improves Developer Productivity - Maxim Tabachnyk and Stoyan Nikolov
It turns out that Google has had its own internal copilot like ML programming assistant for a while now, for eight programming languages, and they find that it provides modest but measurable improvements in productivity:
We compare the hybrid semantic ML code completion of 10k+ Googlers (over three months across eight programming languages) to a control group and see a 6% reduction in coding iteration time (time between builds and tests) and a 7% reduction in context switches (i.e., leaving the IDE) when exposed to single-line ML completion. These results demonstrate that the combination of ML and SEs can improve developer productivity. Currently, 3% of new code (measured in characters) is now generated from accepting ML completion suggestions.
Google of course has the huge advantage that it has a huge code base, with a vast history of of code reviews, famously sitting in a single monorepo, to train their models on. But it’s interesting to see that even with this technology in its infancy, there are noticeable benefits. 3%, 6%, or 7% may seem like small numbers, but 6% of a working year is about three work weeks.
It’s great to see data science core facilities pushing for a growing role for research data management, especially in the service of open science. Here John Borghi and Ana Van Gulick write about Promoting Open Science Through Research Data Management in the Harvard Data Science Review.
Whether you lean towards R or Python, RStudio has been inarguably a force for good in the data science community along several dimensions. So the announcement of RStudio, Inc’s name change to Posit, reflecting a change of focus to include Python (including a python version of Shiny!) is pretty exciting. Jupyter is great and all, but RStudio’s very clear offramp of code from interactive exploration and notebooks into version control and unit tests is extremely helpful, and the python data science community doesn’t have anything like it. I can’t wait to see what the new company dos.
Metrics of financial effectiveness: Return On Investment in XSEDE, a national cyberinfrastructure coordination and support organization - Stewart et al, Proceedings of PEARC ’22
There were a lot of great papers in the proceedings of PEARC’22, and I’ll highlight a few of them in the coming months that I think are particularly relevant for our community.
In this first instalment, the authors take a look at the last six years of XSEDE, and try to answer the simple question “is it worth it for funders to continue funding such efforts”? They focus here on activities and outputs - for the services delivered, internally within the inter-institutional collaboration, and externally to researchers, how much would it have cost to do the same work absent the support of XSEDE?
This requires some thought about what exactly those services are, who would have done them in the counterfactual case, and how much effort it would have taken. The authors describe how they went through this process. For the last they relied on surveys of researchers, and estimates from consortia.
The discussion and the results are interesting, and very believable. (A huge problem in this field is wildly unsupportable numbers - for instance a famous factoid that circulated for a while claiming that the ROI for HPC investment in industry was 50x). For a couple of examples, having a common pool of expertise saved (for instance) local system administrators figuring out how to do the work themselves, and the extended consulting services saved countless hours of research group time. (A favourite nugget - when asking a researcher how much work the extended support services saved their group, if the response was that the work simply wouldn’t have been possible at all without the support, an apparently pretty common response, the authors simply capped off the total amount of efforts saved as 2 people years). The estimated value of the total amount of time saved was 1.5x the amount that XSEDE actually cost. From the authors discussions I felt that this was ab admirably conservative figure.
Like most good papers, the answers provided by the paper suggest new questions:
But even this paper by itself is extremely useful. It’s great to see the community bringing in real business and accounting expertise to produce these kinds of reports to advocate for their services and their researcher community to funders.
IBM Uses Power10 CPU as an I/O Switch - Timothy Prickett Morgan, The Next Platform
Sharp-eyed Morgan notices an intriguing detail in some architecture diagrams out of big blue. An entire Power 10 chip (within a 2-chip package), a not-inexpensive piece of silicon, appears to have all its cores turned off and instead is used to focus entirely on I/O switching in the Power S1022 and S1024 systems.
We’re well into the era where raw compute power matters little in and of itself; rather, balanced throughput across an entire integrated system is what’s crucial. This is why I’m low-key furious that we’re still ranking systems by HPL benchmarks as if how fast a computing cluster can run its “hello, world” burn-in test matters.
Still arguing about tabs vs spaces? 2-spaces per indent vs 4? Pffft. You are like baby. No, I present to you - Fibonacci indenting.
Testing a tool against 14 different database products using Github Actions.
I actually have to do this now, but hadn’t come up with a principled approach to it - juggling multiple committer email addresses with git.
I mentioned the C23 #embed last time - here’s what people have to do to portably include binary blogs in an executable in a world without #embed.
C++20 implemented Python f-string like string interpolation with string::format.
The humble yes command and how a naive implementation can be 10-1000x slower than a fully optimized version, in case you need to output ‘y’ at 3GB/s.
This pure python game of life streams gzip-compressed MPEG video to stdout at 60 1080p frames per second, using bigints for efficiency (!!!).
I like to think I’m pretty open-minded about technology choices, but… the case for C# and .net (as compared to server-side javascript, though, so the bar’s set pretty low).
A NASA video of computational fluid dynamics highlights from 1989.
Facebook Meta hates the leap second.
More than you wanted to know about the tar archive format, and why it extracts in quadratic time.
Maybe more than you wanted to know about the Solaris linkers, loader, and libraries, but ends up being a pretty good walk through of what linkers do, and the ELF ABI.
DuckDB now persists ART indices - here’s how they work.
And here’s how SQLite file I/O works. Fly.io used that filesystem level understanding to develop fuse-based filesystem specifically for replicating SQLite databases across a cluster.
A nascent community (and software tools) for binary translation from x86 to Arm, specifically to deal with the difference in memory models under concurrency.
Nala, a tui-based front-end to apt.
Your python or go command-line tools increasingly have spiffy TUI interfaces - now so can your shell scripts, with charm gum.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.