jonathan@researchcomputingteams.org
Hi!
It’s a busy time of year, as we try to get things closed out before the holidays. For a lot of us, outlines of opportunities and connections for the next year are starting to come into view; if that’s the case for you, I hope you like what you are seeing!
For us, the familar challenges of negotiating multi-institutional (and multi-sectoral!) collaborations are starting to yield to steady effort, and the exciting work we want to do will be beginning in the new year. It’s an exciting time, but means the newsletter is late again this week.
Next issue will be the last one for 2021; that will give us all a little bit of a breather to rest and recharge, and start again fresh in 2022.
For now, on to the roundup - the second-last of 2021!
Leadership Word of the Day: DISAPPOINTED - Ed Batista
Our role power as managers or leads imparts extra weight to our words to our team members. So it’s important to choose carefully. Batista encourages us to make sure the word “disappointed” is in our toolbox for when we need to give negative feedback or discuss negative situations:
The Power of Performance Reviews: Use This System to Become a Better Manager - Lenny Rachitsky, First Round Review
A guide to quarterly planning (plus a template) - Nicole Kahansky, Hypercontext
Here’s potentially timely resources: a couple of articles here on periodic meetings that may well be happening for many of you in the coming weeks, with templates.
In the first article, Rachitsky describes his annual performance review, with a Google Doc template for what he shares with his team members. The template gives a (categorical) rating, lists accomplishments and peer feedback, and then highlights their greatest strength, gives high-level feedback, and digs into two development areas for the coming review period, each with summary, concrete examples and suggestions, and what success would look like. Then there’s a “what’s next” and “when” for them - could be new role, or new responsibilities.
Rachitsky sees a few common failure modes, including not spending enough time preparing, not providing really substantive feedback, having a one-sided conversation or not doing them at all, and not having a follow-up plan. He gives some examples of how to do followup, creating a two-sided followup plan which can then be touched on in one-on-ones or in separate meetings.
In the second, Kahansky gives an outline for a quarterly planning meeting. Quarterly is an excellent cadence for planning (and even performance reviews) for a lot of research computing teams; long enough between meetings that meaningful amounts of work can be done, but short enough to be able to react to our always-changing environment and needs. Kahansky outlines a five-point agenda:
Be Intentional About How You Spend Your Time Off - Laura M. Giurge and Vanessa Bohns, HBR
With the holidays coming up, and another tough year for some of us, it’s important to take the time to recharge. But just not having meetings for a while doesn’t automatically refresh us. Setting (flexible) goals for things to do over your break and reconnecting with people are demonstrably successful ways to spend time recovering and refreshing yourself, as Guigre and Bohns show us.
Modern biotech data infrastructure - Brian Naughton, Boolean Biotech
If your team is in the position of potentially supporting small new biotech firms, for example as spinoffs from University research, here’s a very pragmatic point of view of needs and challenges from the head of data at a larger firm.
Expanding HLRS Academic HPC Simulation Training Programs to More Target Groups - Döpper et al, Journal of Computational Science Education
Here’s an article describing Stuttgart’s HLRS supercomputing centre’s expansion of their core academic HPC training program into schools (“Simulated Worlds”) and industry (“Supercomputing Academy”). They’re both blended courses - with attendance days, self-learning phases, supervised hands-on exercises, and webinars; but targeted to the different audience.
Their school training product, Simulated Worlds, started as an HPC outreach program which turned into simulation more generally. They rely on local champions (“HPC Ambassadors”) to help them make connections to curriculum, and help them understand what does and doesn’t work in the classroom with the school-aged audience.
For working professionals, the Supercomputing Academy is a little different. It’s a collection of modules, targeted for different “certificates” for HPC Users, Developers, Administrators, and Experts, each with specific learning objectives. Modules bookend with an on-site attendance day, with self-learning between, and weekly virtual seminars and assignments to give structure. Here the local champions are brought into roundtable “expert workshops” to help define industry-relevant learning objectives.
The 13-page paper goes into this in a lot of detail, so if you’re thinking of spinning up or improving similar training programs, there’s a lot to dig into.
Supercharged high-resolution ocean simulation with JAX - Dion Häfner
Writing Simple Python GUIs for your Command-Line-Phobe Coworkers - Nash Reilly
A couple of Python entries this week.
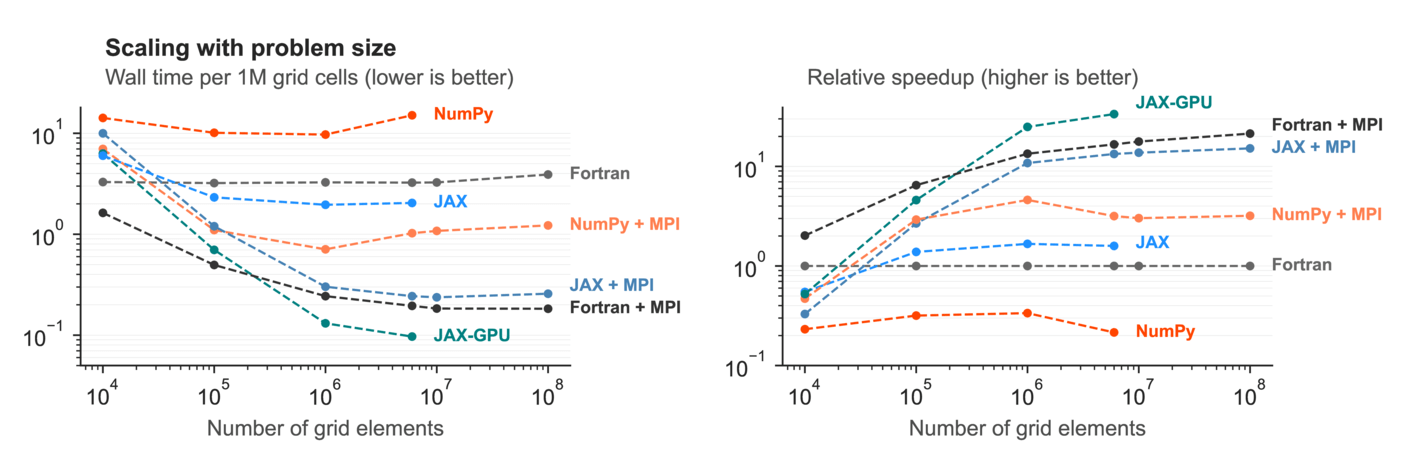
In the first, JAX, a set of tools designed for AI/DLL work, is applied to CFD. We’ve talked here about JAX before [#34, #98] - it started as an auto-differentiator (already useful for numerical computing work) but has turned into a more general Python JIT compiler for GPU or CPU.
Häfner writes an article suitable for those new to CFD simulations about how stencil calculations are done, and how a package he wrote, mpi4jax, lets the JIT compiler know about halo-cell operations, so that the entire fluid dynamic backend can be compiled. This means the Python ocean model Veros now supports JAX as a back end, and can run in parallel on CPUs and/or GPUs. The result is Python code that runs roughly as fast as Fortran on CPUs, but also can automatically take advantage of GPUs.
In the second article, at the other end of the scale of complexity, Rielly shows how to bundle up simple CLI python scripts for doing modest data-handling tasks in a way that’s easy to hand off to a researcher using PySimpleGUI to give it a cross-platform UI and pyinstaller to turn it into an easily-installed tool.
Avoiding Premature Software Abstractions - Jonas Tulstrup
Tulstrup reminds us that abstractions have cost, in explainability and code that has to be maintained. You Aren’t Going To Need It is a decent default principle.
Run a website off a Google Sheets Database, with Hugo - Mark Hansen
It’s not that MySQL or Postgres (or clickhouse, or Mongo, or Influx…) are bad, or even that SQLite or Google Sheets (or DuckDB, or Airtable…) are good; but in research computing we have a tendency to do things “right” and “scalable” even when something much simpler does the job perfectly adequately.
So there’s this huge gap in research software, and research data management, between what happens when the researchers are left to fend for themselves (mailed-around Excel spreadsheets) and what tends to happen when we get involved (Architected Solutions based on PostgreSQL), leaving a lot of perfectly good solution space in the middle. This is why basically any mention of embedded databases earns at least some mention in the newsletter, and for my repeated lament that there’s a lot of folders of CSVs, and a nontrivial number of MySQL databases, that could usefully be a sqlite file.
Here Hansen talks about his development of Profilerpedia (#95) as a Google-Sheets backed service, which he pulls data from using the Charts API and runs a pipeline on when building a static website hosted with Netlify. As he points out, Sheets is a perfectly cromulent solution for some problems - easy for people to contribute to (with simple but effective authN), comments, public read-only, forms for data collection…
Verneuil: S3-backed asynchronous replication for SQLite - Paul Khuong, Backtrace
Relatedly, it continues to be interesting to me that SQLite is getting more traction in industry, and having new tooling built around it; here we have Verneuil, which is apparently a second(!) S3 backing to SQLite, basically maintaining SQLite as a common interface but also keeping data in S3.
Launch Jupyter Notebook on Fly - Fly.io
Edge- and cloud-computing companies are starting to have increasingly interesting free tiers (e.g. see Oracle Cloud’s), perfectly suitable for hosting small but real applications for research groups. Here Fly.io [#70] lets you deploy a (one-at-a-time) Jupyter VM on their edge-based infrastructure, close to your users, within their free tier.
AWS Goes Wide and Deep with Graviton3 Server Chip - Timothy Prickett Morgan, The Next Platform The Rising Tide of Semiconductor Cost: It Isn’t Transitory - Doug
A lot happened at this week’s AWS re:Invent, but this and related announcements were the most interesting from a systems point of view.
The Graviton3s look like genuinely cool systems - they are Neoverse-2 based which means they have support for the Scalable Vector Extensions (#72) and seem to give really good floating point performance as a result, they have huge memory bandwidth (300 GB/sec), DDR5, PCIx-5, all good stuff. They’re in preview now if you’re curious, and Morgan as always has as good a deep dive as currently available information allows.
But apart from the speeds and feeds, this is really just one data point reflecting a larger shift. This is an arm server that would be a very credible candidate for any HPC system, not just an experimental low-power rack.
Less subtly, AWS announced a flurry of new instances this week, and a lot a lot of them were labelled with an ‘i’ for Intel - c6i, m6i, r6i - like the AMD nodes have always been tagged with an ‘a’, and the graviton nodes with a ‘g’. We’re now solidly in an ecosystem where Intel - and even x86! - isn’t the default any more, after 20 years of it being a near monopoly. Leaving that monoculture is going to mean more work for systems and software teams.
But the opportunities of matching the right system to the right problems are also going to be growing. It’s an exciting time! In the second article, Doug explains why we’re seeing this diversity now - Moore’s law is dying, the free lunch of more transistors for the same price is over, and for better performance on different workloads we’ll need different kinds of systems.
Introducing CentOS Stream 9 - Rich Bowen, CentOS
Another transition - RHEL, and now CentOS, are now officially on the continuous stream approach as opposed to the more traditional release model and cadence.
I’m optimistic that RHEL ends up bringing hardware vendors along with them - that vendors start releasing more frequent driver updates that track the RHEL point releases, instead of using the infrequent release schedule of RHEL as a lazy excuse to not touch their code for months or years at a time, holding HPC systems everywhere back on old OSes.
If that happens then I think this transition will be inititially painful but eventually good for everyone. Users will have more recent OS images to run on, system teams will have more current systems with less awkward patching, and we can start moving to more automated updating of packages a la spack or similar.
Everything you ever wanted to know about UDP sockets but were afraid to ask, part 1 - Marek Majkowski
As Majkowski points out, QUIC (powering HTTP/3) and some wireguard tooling is using UDP now, and so is having a bit of a resurgence of interest. If you want to know more about UDP, this is a pretty good place to get started, from a team that knows their network traffic.
EFA is now mainstream, and that’s a Good Thing - Brendan Bouffler
This is an article from last month, but it’s even more true after re:Invent than it was then. 32 of AWS’s instance types (double what was publicly announced at time of writing) support their Elastic Fabric Adapter, AWS’s approach to speeding up large-scale parallel computing jobs without moving to Infiniband (as well as speeding up access to storage). AWS clearly sees EFA as the way to go, while Azure continues to double down on Infiniband. They are two clearly different approaches with different tradeoffs, and I’m really interested to see how it plays out. Will there be different use cases clearly favouring one or the other? Or will one end up winning?
DevOps in academic research - by Matthew Segal
Here Segal, who worked for 18 months as a “Research DevOps Specialist”, talks about his work in moving a 20kloc MCMC python modelling package for infectious disease models, in a development and systems environment that wasn’t prepared for the sudden urgency and rapid release cycles that were needed when COVID broke out. There were no tests, making development slow. A lot of manual toil was involved in calibrating updated models, which was fine when they were for a paper that took months to write but suddenly much less ok when stakeholders wanted updates weekly.
The article describes a very mature approach to introducing devops into an academic group - mapping the workflow, introducing very basic testing (“smoke tests” - does the code blow up?) to get started, adding automated CI testing, improving performance (useful in its own right, but also makes it easier to get people running tests locally), adding task automation, adding diagnostic visualizations, and introducing data management practices. Notably, while there are tool recommendations, the focus is on processes and enablement.
As soon as basic processes were automated to the point where manual toil wasn’t the limiting step any more, the slurm cluster the group used became the bottleneck, and the team had to move to AWS + Azure (GitHub Actions) to get their new fast, dynamic, workflow running. I think it’s likely a problem in the medium and long term that so many institutions don’t provide access to flexible and dynamic infrastructure, relying solely on systems that have been highly tuned and optimized for asynchronous batch runs. Once early adopter groups get used to going elsewhere for services, it’s going to be hard to bring them back.
OOPS writeups - Lorin Hochstein
Hochstein gives the outline and an explanation as to how his team in Netflix write up “OOPS” reports, essentially incidents that didn’t rise to the level of Incident Response, as a way of learning and sharing knowledge about things that can go wrong in their systems. It’s a nice article and provides a light-weight model to potentially use.
His outline, blasted verbatim from the article, is below. I particularly like the sections on contributors/enablers and Mitigators as things that didn’t cause the issue but made it better or worse than it would otherwise have been. If this is of interest to you, or you’re thinking of starting some way of formally writing up “events” that happen in your systems, the article is a short and interesting read.
There’s at least 350 million lines of running COBOL out there.
Oh hey, do you remember DESQview/X - DOS, but with X11?
Libtree, like ldd but will tell you why libraries were/weren’t found.
You like writing assembly code, but want an easier time prototyping/testing out ideas? asmrepl is a repl for assembly code.
There are more modern tools around out there (ANTLR comes to mind), but if you want to quickly add some parsing and lexing to some existing C code, it’s good to know what flex and bison can do.
Vortex: A full-system RISC-V based GPGPU processor, ready to go on your favourite FPGAs (as long as your favourites are the Intel ones).
Nice article from earlier in the year tracing out the history to the adoption of Command Palettes, like the one in VSCode.
In this week’s “Your scientists were so preoccupied with whether or not they could, they didn’t stop to think if they should” news: you can now compile your C code into… Excel.
Singularity Containers are now a standard of the Linux Foundation and named Apptainer, with a renewed emphasis on enterprise use. Good? Bad? I guess we’ll see.
Ten simple rules for effective presentation slides - common advice, but tuned specifically for scientific presentations.
I really like the JetBrains IDEs, but I prefer the VSCode editing experience. JetBrains has a new architecture in beta, Fleet, that (like VSCode) better separates the editor from IDE services. As a result, one IDE can support all of their languages. Very curious to see how this goes.
Good-looking compiler course from CMU.
Uncompressing a gzip file by hand.
A debugging story, notable for novel use of git bisect to figure out which 488 environment variables was the problem.
Capability map for SRE teams.
And that’s it for another week. Let me know what you thought, or if you have anything you’d like to share about the newsletter or management. Just email me or reply to this newsletter if you get it in your inbox.
Have a great weekend, and good luck in the coming week with your research computing team,
Jonathan
Research computing - the intertwined streams of software development, systems, data management and analysis - is much more than technology. It’s teams, it’s communities, it’s product management - it’s people. It’s also one of the most important ways we can be supporting science, scholarship, and R&D today.
So research computing teams are too important to research to be managed poorly. But no one teaches us how to be effective managers and leaders in academia. We have an advantage, though - working in research collaborations have taught us the advanced management skills, but not the basics.
This newsletter focusses on providing new and experienced research computing and data managers the tools they need to be good managers without the stress, and to help their teams achieve great results and grow their careers.